Las Vegas 2019
Incident Management Meets DevOps
Learn how we are applying DevOps principles to innovate Incident Management Process, using a homegrown "Runbook as a Service" platform. We are empowering engineers to automate restoration of known issues using known solutions by leveraging their runbooks.
SA
Surya Avirneni
Senior Manager, Lead Software Engineer, Capital One
BG
Bhavik Gudka
Director Software Engineering, Capital One
Transcript
My name is Bobby , director of software engineering, capital one. I'm currently in the Cartec space, managing Sidey library engineering group, as well as another team dedicated towards authorizations platform. I have a colleague today with me. Okay. So do you have any
Thanks Berbick? Uh, my name is and I'm a software engineering lead, uh, for capital and technology operations center. Uh, so I'm glad here and, uh, we're glad to have all of here.
Thanks. So thank you all for coming here. I know it's right after lunch. Uh, let me just quickly check, uh, because after lunch people get sleepy, so let's see how sleepy are we are. Good afternoon. Okay. From the last rose. I don't hear that. Good afternoon. Okay, cool. We have a wide awake audience here. So,
So how many of you are developers here? Quite a few operations Production support, And, uh, how many of you are DevOps engineers? Come on guys. All of us are,
So, uh, let's start with this presentation with a quick refresher on what DevOps is. Uh, most of us know what DevOps is and most of us practice it every day in our lives. Uh, so as you, as you know, like DevOps is basically a philosophy and it's, it's, it's a practice where you bring in developers and operations together, uh, to shorten the product life cycle, right? And, uh, it, it enables enterprises to deliver features much faster to the market. And at the same time, it creates a feedback loop for the developers, a much necessary feedback loop, which was non-existent before the days of DevOps. Uh, so they can, uh, release high quality features, uh, rapidly with, uh, and, and which also aligned with the business objectives for the enterprise. Uh, maybe let's move on. So some of the, uh, benefits of DevOps and like, what's, what's in it for you as a developer, right?
Like you, you get those continuous integration and continuous deployment capabilities using which you can rapidly release new features. And, uh, and what's in it for the product managers and the business executives, right? Like, as I mentioned is, uh, earlier, like the faster time to market and creating those greater experiences, uh, for your customers and, and reaching them first is, is the important thing for any business to grow and capture the audience. Right? And, and that's, uh, evident in today's world where companies like us and many other companies are excelling at reaching their customers faster and creating those experiences for them, uh, which can, uh, keep those customers
For a time with them. So that's about developers and product managers, and I'm hoping there might be work managers around here. They all see the benefits of DevOps. But when I talk to operations folks or incident managers, they don't give a damn about dev ops because so far it has not benefited them. So the question today that I want to ask, or some of you might be asking if you are on the incident management side, what is the OBS giving you? When I say you, as in, if you are an incident manager or operations guy, how has DevOps helped you? Because now what is happening is left and right code is moving into production. So a lot of changes are going rapidly, but then there are incidents that are issues that will happen all the time. So while the speed of development has gone up, you have not seen the full benefits of DevOps for the other side of the fence, which is the operation side or incident management side. So today we are going to talk about how DevOps can play a role in incident management. We are going to talk about what is incident management? What is the life cycle of incident management? What are the goals of incident management? How has incident management evolved over these years and how can DevOps play a role? So I'll say, okay, so what is incident management? Anyone, any idea anyone wants to talk about? Like, you know, one, give me one or two words. When you talk about incident management, anyone
These are some of the words I hear. And I talk to people about incident management, boring labor, stress developer, say, I hate it. Some folks who are already in into management, they say, it's a thankless job, escalations you blame others for incidents. It's waste of time. I used to say that at some point, it's a waste of my time. Nighttime calls. How many of you developers out here feel that it's all nighttime business? You know, the woman, your incident management, oh boy, I just wake up at night and do things. No life I've heard that, you know, there's no life. Uh, and of course there are some people who love it, but the sentence is, I love it when I'm on vacation, they love incidents, but only when they're out of town. So that's what generally people, that's how people see incident management. What is the incident management life cycle? It's, it's a clock. I mean, that's the first thing that comes to my mind. When I talk about incident management, that it's a clock. It's a time that's like, you know, clock is ticking. The problem start for our customers. And from incident management perspective, we have to make sure that the incident gets detected. We have the right folks or right tools to solve that problem. And finally, the problem gets solved. So which means
You detect a problem, you get the right people or tools mobilize, and then you solve the problem. Most of the times solving a problem might take five minutes, 10 minutes, 15 minutes. But the things before that might take ours. And what is the goal of incident management? The goal of ins management is use time to recover problems because any company will have one goal, which is always on. We want our customers to be happy. Are you can have faster time to market, but you have failed. If there are downtime, if there are incidents and you cannot resolve those incidents quickly for our customers, if you cannot give them always on experience. So how do you reduce that time to recover? Which means you reduce TDD time to detect TTM time to mobilize the right people. And finally time to restore the problem or trying to recover in general. We also want to reduce the incident count, but today's topic is not about that second bullet, because it takes a lot more to reduce the incidents. But we are going to focus on when there is an incident, how do we reduce the time to recover?
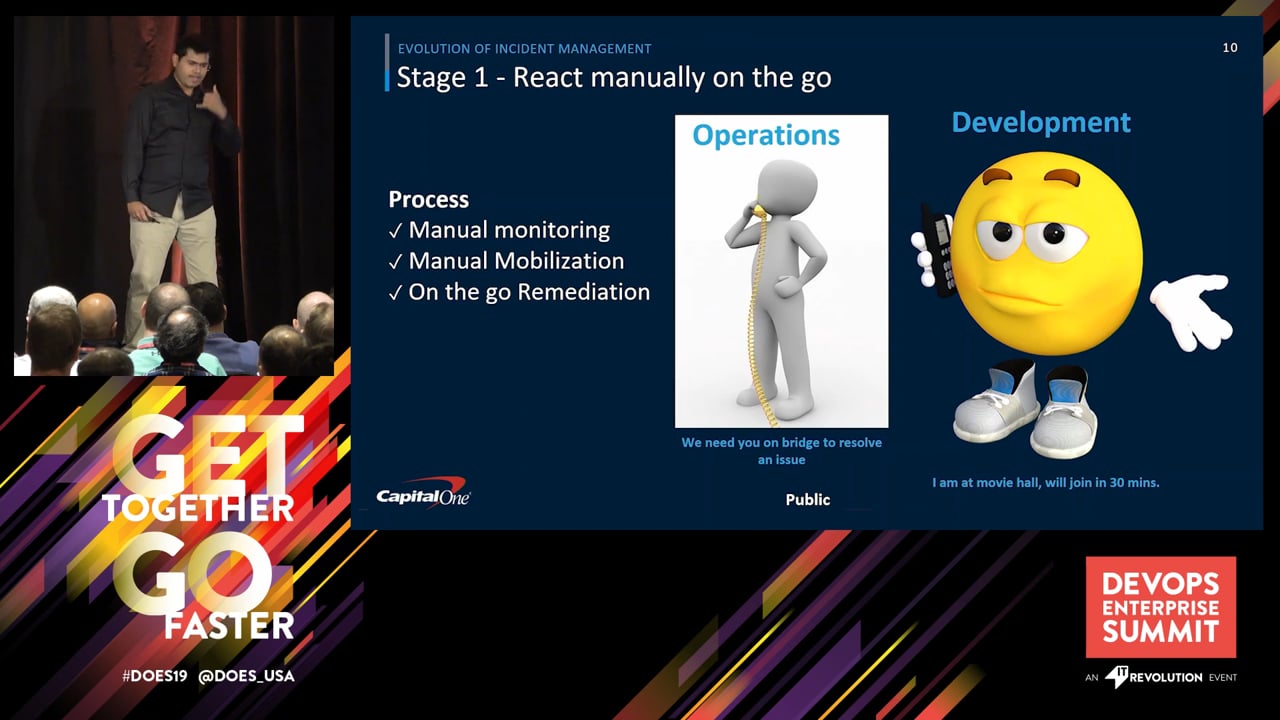
So before I talk about that, what we are going to do is now we are going to talk about how incident management has evolved over these years. So we talk about the dinosaur ages, you know, like 15, 20 years back, how incident management used to happen. Let's assume that Syria is a developer and let's assume I'm an incident manager or operations guy. I get a call or I get to know somehow that there are problems in my system. So let's do a role-player. Okay. Uh, I'm an assistant manager. Somebody told me somehow that Syria is the guy who can solve it.
Hey, Belviq hello?
Hey, he's Hey, we are having lots of problems. Um, and it looks like we might have to fail out our application to our secondary region. We need you on the call. Can you please join?
Hey, Belviq I'm at the beach. I cannot join the call right now.
Um, okay. Uh, this is important, man. You know, uh, your manager is also on call with me. We, we need you, but I
Didn't carry my office laptop with me. Sorry. Belviq
Come. Okay. Uh, how about just guide us, you know, like, can you, there's a lot of background noise, you know, can you come to a more, a better area so that I, I can talk to you. Okay. Give me a 15 minutes. Okay. All right. It's 15 minutes or 16 minutes now 16 minutes already.
Hey Barbara, give me another five minutes.
All right. So of course I'm not, not going to finish their whole call, their joins. He guides us. And the problem is the problem got solved in like five minutes after he joined or after he gave us a direction, but it took us like these 20 minutes. And this was a happy bot. What if it would have been one hour? Sometimes we have heavy. Anybody has anybody remember that time? Okay, there you go. That's great. So what happened there? Process manual monitoring manual, and on the word remediation on the fly, he wrote something on phone and we did that. What are the results? So
What did we observe here? Right? Like with manual monitoring. And that's how you used to monitor our systems like back in the days and it's, it causes slow detection of issues. So it cannot automatically detect a problem unless some one reports to you, whether it's your agents or your call center associates, or your customers, uh, you know, reporting those issues over call to you and the mobilization as we have seen, it's almost not there at all. Right? Like someone has to call someone and then they have to just desperately wait for this person to come onto the call and fix the problem. And of course the remediation has been slow because we couldn't mobilize the right personnel at the right time. And even in that, that took time, uh, for remediating the problem. So that's, that's the lesson learned here, Bobby
And things improve. Some of the monitoring automation helped, but everything else was still not that great. One thing that might've changed was now the steps that he was telling you on the phone, he started putting that in some form of runbook or a toss G or a guide or an operational guide. So, which means whatever he was going to tell me on phone. He has put that on paper and I have a document somewhere. So let's look at stage two, react manually using some runbook Greenberg. We'll have some statements that are written in English, some steps, and let's see how it goes.
Hello? Babak
He's Rhea. We are trying to fill out an application to a secondary region. I have the run book that your team gave me. Um, I followed all the steps. Now what we have seen is yes, the error rate has gone down, but we see a lot of latency there. Something is not right.
Hey, can this wait?
No, Syria, this cannot wait. Our customers are waiting there.
Why don't you try the, the document that is in some XYZ site?
Hold on all the steps there, man. Any, any idea? Why would there be latency? Because I don't think that was expected and he can get towards,
So did you feel over all the services?
Um, yes. Whatever was on the guide had failed, all those things. What, like,
Did you move the caching service to the other region as well?
Which I can get back to you. All right. I look at the caching service and yes, it was not failed over and I do that and I call him back. Here's Maria, thanks for the dip, man. Uh, that helped, but why didn't you put that in the run book?
I'm new to this team. I don't know. Oh,
Okay. Can you, can you please get the document updated for me?
Alright. Yeah.
Afterwards. Thanks man. Okay. So automated monitoring manual mobilization. I still had to get that document and then actually had to talk to the person. When I run into issues planned remediation, there is a good thing. You are, at least Remington was planned, not on the fly. Is that not, not what we exactly wanted. Stage three things have improved. That document is not a document anymore. It's a script, but it's reacting using a script, but it's still manual intervention required. So again, the third place, I am not able to download the script.
Hi,
I'm trying to fill out this application. We have some issues going on. Um, I'm not able to download your script, man.
Did you get to the right strip and the right URL that I sent you last week?
Yeah, I think so. You know, let me get back to you. Okay. And then after doing some more digging and all, finally I get a proper URL. It looks like the team had sent some URL that we missed. Here's Rhea, man. Uh, barbecue. Again, I found the new URL that you sent me the email. Sorry, my bad. Sorry for calling you so late, but just wanted to let you know that things are good. I ran your script and it's, it's fine. Thanks. I hope he never got
Me again,
Automated monitoring manual mobilization. I had to still find that script somehow yet. Of course I was not. Depending on, I was even on the script, I could not find a script. I can depend on Sonia automated remediation because script is doing that for me, resert fast reduction, slow or fast mobilization, depending on the day, it's no or foster mutation, depending on the day.
Then we said, okay, fine. You have a known problem. We have a known solution, but we still have this manual business going on. How do we fix that? And we said, can we use DevOps way to do incident management? What was DevOps about? He explained in the previous slide, it's shortening the life cycle of the software development or business goals. This is my definition of incident management using DevOps. I don't think you'd find it anywhere. I just tweak those words and said, what if I had to use DevOps in incident management shorten the incident management life cycle that we saw earlier, the three or four steps while we living features fixes in a Bates frequently in close alignment with operational objectives. And what is our approach? Our approaches automate end to end process similar to a CACD by a blind, the three stages of production outage detection using a trigger using the detection to trigger a script.
So find a script and then trigger that script, solving, known problems using known solutions automatically. Of course, sometimes you want will be required if the script fails for whatever reason, part in that case pays the relevant teams automatically for unknown problems. This is how it looks like the flow chart, monitoring tools. They do their job of automatically during the problem, the events will come in and then there'll be a runbook as a service platform. If it's a known problem, that is where is known run book. Rainbow can be a script. We invoke that it's a new problem for which I cannot find the script. Then I just page the on-call. But you're, we are trying to cut down the time it takes to mobilize a script or mobilize a person. If the script cannot be fun, reside, fast detection, fast mobilization of resources. It can be a scripted again with team, whatever asked remediation of known issues using known actions. But of course, if it's an unknown issue or maybe it's an ownership unknown solution, first time, it will take time. But once we do it first time, then second time it should be automatic.
So, so why did we build this platform? So as Bobby explained earlier, like when you solve known issues with known remediations, which are automated, you're reducing the overall downtime or the, uh, applications in stability issues, uh, and you're almost, uh, helping your customers, uh, access your apps without any downtime. So imagine this, uh, if you put runbook as a service, as an enterprise service, uh, out there for all your, all of your tech teams to come and automate the known problems. So in the previous slide, uh, as you've seen, there was an issue where, sorry, so as you see here, like for known problems, we are able to exhibit a runbook, which was in the registry and we could have fixed the problem, but what about unknown problems at that point in time? Right? So you're paging someone to come and fix the problem, but, uh, at the same time you can now apply learning there.
So what was the fix? Was this a known problem? Will it reoccurred all the time? And can we solve it at the root or is it how we have to live with it? Right. So that, as the question, when you ask that question, then you can implement a runbook for that problem or that scenario. So, so why did we build this platform? So we wanted our developers and tech teams, uh, to don't have to worry about another automation solution. Instead, we wanted them to use existing automation tools that they already familiar with and they use in their DevOps pipelines. So, and this runbook has a service platform. We'll create a unified runbook language across the company. So, which means if you're in team here or team hundred, you all speak about the same language when you talk about the runbook. So when you move across teams, there is no confusion. And this abstraction also leverages all existing toolset. Uh, so you can just, uh, use the existing automation. Sometimes it may be a shell script. Sometimes it may be a more advanced Terraform job or something like that.
And, uh, with deep integration into enterprise functions, like change management and incident management processes, uh, we are able to follow all the enterprise policies in respect to those processes. And at the same time, reduce the downtime of our applications. And then the, the constant learning that happens in this life, in this life cycle of Iran book, uh, will help us to automate more and more run books as we progress across the company. And last but not the least is that this becomes a hub for all enterprise run books, which means we can now promote reusability across the enterprise, uh, for all similar tech stacks. And which means you can just have one template created for all known problems in a type of tech stack. And now you can apply this in hundreds of places, uh, at the same time without teams having to build their own automation to fix these problems.
And so some use cases we have seen so far, uh, uh, the multi lesion, failover of databases. So most of the databases won't replicate across regions from for just the sake of cost, right? So they operate in one region and in region outages can happen and the availability zones in the regions may have problems. So in those cases, you have to move them over to the other region and it involves multiple steps. And we don't want someone to log in, uh, to your cloud provider or your data center and do those steps manually, right? So, so that's one of the, uh, like the straightforward use case. We can apply across tens of, uh, applications across our, uh, company and automated, automated disaster recovery. So you can easily automate disaster recovery steps, and we don't have someone to perform manually all of those actions. And of course, like they can be other items as well. But, uh, the most favorite of mine is automated diagnosis and troubleshooting. So this helps, uh, any company which implements automated, runbooks save tons of time in troubleshooting and, you know, pinpointing and triangulating that problem. And especially when you are an enterprise with large tangle of applications, which are dependent on each other. And so that's, that's where, uh, you can save tons of time and, you know, get closer to the remediation rather than spending all the time, uh, during an incident call, just troubleshooting an issue. So you want to comment on the last slide.
Yes. Finally, our goal is just the same as coal of any company. I hope every company has this goal that we want to keep our enterprise always on. So whatever we discuss in the previous slides, we can build this platform. And if we can have standard way of every team have their own book, because thing from a developer's perspective, when you are working on a problem, and you're trying to fix something in production, there are some protocols you need to follow. You have to file a change order. You have to file a for auditing and all you have to alert people, but the run book as a service platform, we'll do all those things for you, you as a donor. But I only focused on my problem and the fixed that only the logic that is going to fix my problem and not worry about different things that also need to go during our incident management process.
Uh, and then more importantly, once there are more and more run books, um, we can also do some machine learning out of that. Once we have the data, we can also figure out, is there any application that just keeps on patching stuff? Because sometimes what will happen is you will not realize in the manual world that a team is just taking shortcuts and they just keep patching their problem by just doing the same thing again. And again, if I have this kind of a platform, I can always pull metrics and figure out that a team, a God, this problem, like 10 times a month, and every time is run, book was run. That's not good. Something is not right about it. So, which means while we are encouraging people to put runbooks, they're also kind of finding out if they are doing too much of it, which means they're not fixing the root problem like this space cleanup.
It's okay for an book of a disc space, clean up is running. Let's say once in six months or once in three months fine. But if it is running every day, it means there is something wrong. They're not rotating their logs, or they're writing a lot of junk in their log. Something is abnormal about it and they just keep patching it. Another example will be failover situation. If somebody is feeling what every day, something is not right. Yeah. Failure can happen once a month, once in six months, once in three months makes sense. So while we'll encourage people to build their own books, we'll also be able to pull metrics that how many people are actually just patching or putting patches in their software and not building a good software. So there are many advantages that so ML can have that another aspect of ML would be.
Um, if you already know that a run book is written properly for one team, and there are other events for other applications that are coming in, or they don't find a matching run book, maybe we can tell them, Hey, look for your event, this other Dean, they have a run book for their event. Your event look very similar. Maybe you should just talk to each other and figure out and solve that. So there are a lot of advantages. If you have a platform, if you have a registry in one place where anybody can learn, because as a developer, I want to learn from my mistakes, but I also want to learn from other's mistakes. I don't want, I want to make sure that what problem others had. I don't want that problem. Or maybe I can reuse that solution if that problem is valid for me.
Thanks, Berbick. Uh, so, so as part of Capitol and talk, which, which is the technology operations center, we are responsible for keeping the lights on in the company. And as we go into 2020, we are going with some bold goals on how we can automate most of the runbooks for all the known problems. And at the same time, as Bobby mentioned, use machine learning to apply those automated runbooks across the company for similar events. But again, our ultimate goal is we want to see that day when we don't have to have it on book, and there is no issue, but, uh, software can fail. Systems can fail. So it's always handy to have some runbook automation in place so we can, you know, respond to those events, uh, whenever such things occur. That's it, that's our talk
Questions.
Uh, my question would be what is the ratio between known problems and unknown problems if you've seen any decrease in the number of unknown problems or because if you have very little known problems, solution doesn't really help. I was wondering what's the ratio is there.
Yes. So right now we are in very early phase of this platform. So you're right. You have more, a non problems and less known problems, but it's not that volumes are unknown. It's mainly because we don't have a matching runbook because it's a rule-based engine. And on day one, when there are not on books, there'll be no rules. It's the first one becomes those events will have a matching book. Others will not as more and more people will adopt and build more on books. That ratio will get better. Does that make sense? Okay.
Are you guys a great presentation, really? Like the way you presented it was a complicated topic, some of the use cases that you showed in your slide. And I took picture of that, uh, it was, uh, dis basically now, as you discussed, right. Or restarting an instance. So if you are an automated runbook to do that, uh, restarting an instance again, and again, might not attach to the root cause. Right. You might end up in a bigger time bomb. I've experienced that myself. So going in future, as I see your future perspective, do you guys plan to force kind of a policy around saying, Hey guys, you start restarted this eight times in this last month. Yes. We are not going to do that. Uh, and some metrics on that or a data point on that if you plan to do that, is there any plan on what platform you want to use that? And my second part of the question is, can you briefly tell me, like, not the big list, but what are the underlying tools like slack Jenkins? What have you used to implement this?
Okay. So I can comment on them. Uh, so, so that's exactly where we are going for, right? Like once you establish a platform and once you start seeing those use cases, uh, for remediations being happened, uh, we want our problem management practice to pick up those use cases, uh, which are not relevant, or rather put it this way. They use cases like disk space, cleanup, or restarting instances, uh, may not be more relevant in the world of cloud, uh, when, when you have auto-scaling and all these features. Uh, so that's where we want that metric to develop and our problem management, uh, to take that into effect. And we'll apply that root cause analysis across the teams, uh, as an enterprise, uh, standard. And to answer your second question, uh, you can use any automation behind the scenes. We are just using, uh, serverless, uh, Lambdas and step functions to do it. And then we integrate with other, uh, you know, toolkit across the AWS cloud and monitoring.
Oh, your first question though, I do have different perspective there. I already covered in my last slide that eventually, if somebody is patching too much, it will stop them because of the metrics we'll pull out. But there is always going to be a gray area. When you know, that team has to fix it the right way. Let's say they say we need three weeks or four weeks or whatever it may be during those three or four weeks. We know that that problem can happen few times. Let's say 10 times during those 10 times, how do we make sure that a known problem is solved by a shorter known solution with minimal intervention as quickly as possible? So, which means it's okay to have a patching kind of run book for some time, but not forever. Yeah.
Uh, Sue and Broderick. We have time for two quick questions. Anyone else with any remaining questions, please find our presenters right after the presentation wraps here, we have two last questions that I already have those people here. Thanks.
Um, so you said you're using machine learning or artificial intelligence. We will,
It's our roadmap.
So typically for using the machine learning models, you need a lot of data to do that. So how much data are you really planning to capture from the runbook information? It will not be really not many, right?
Yes. So it may not be just the runbook information, but we already have incident information from the past and what all actions were performed during those incidents, uh, as part of the incident activity and incident restoration processes. So we can apply natural language processing and all those, uh, incidents and textual, uh, you know, analysis to come up with automated recommendations. And at the, and of course the runbook information will compliment that.
Uh, if I look at it, like maybe if you take the, even the history for the past 10 years might not even see how thousands, 10 thousands of records. Right. Um, I believe machine learning works. If you have more than that data, like millions of records. Yeah.
You're absolutely right. And that's why, if you said, it's our target, we are not doing, we are not, we have not started doing it right now because it's just a new platform. They just started using it. But as we get more and more data, it's not just about the runbook itself. It's about how many times they're on book is getting triggered. Even that kind of data will be helpful.
Thank you.
Hi. So my question here is I understand that this is like a new platform that you guys have started building on, but have you explored the possibility, like this thing, solving any kind of application issues like, uh, when you have like a multiple microservices in a play and then let's say one service is down or, uh, taking long time this, uh, they helpful because the use cases you have brought so far, it's like more around infrastructure use cases that any ways like a cloud platform provides you like a system like that is a highly available, like if auto scaling same, when there's like instance goes down or database fields over happens. Like if you guys
You're absolutely right, you can automate anything. So yeah, this is how I see it as a Dota blur. My Dean is getting involved in some issue application issue for the example that you mentioned, if they are following 8, 9, 10 steps. And if they know that that's what they are going to do for whenever that issue happens, they can automate that. Which means you're on book is not always about fixing a problem. You're on book can also be about to his point troubleshooting. So you want data from three or four different places to be able to make a decision. So you can make Arango out of anything where, you know, you have a known problem and you have known set of steps that you would like to do, make an onboard of that. Even for troubleshooting. In fact, there might be more and more troubleshooting then for actual fix.