Virtual US 2022
Why Does Capital One Test in Production?
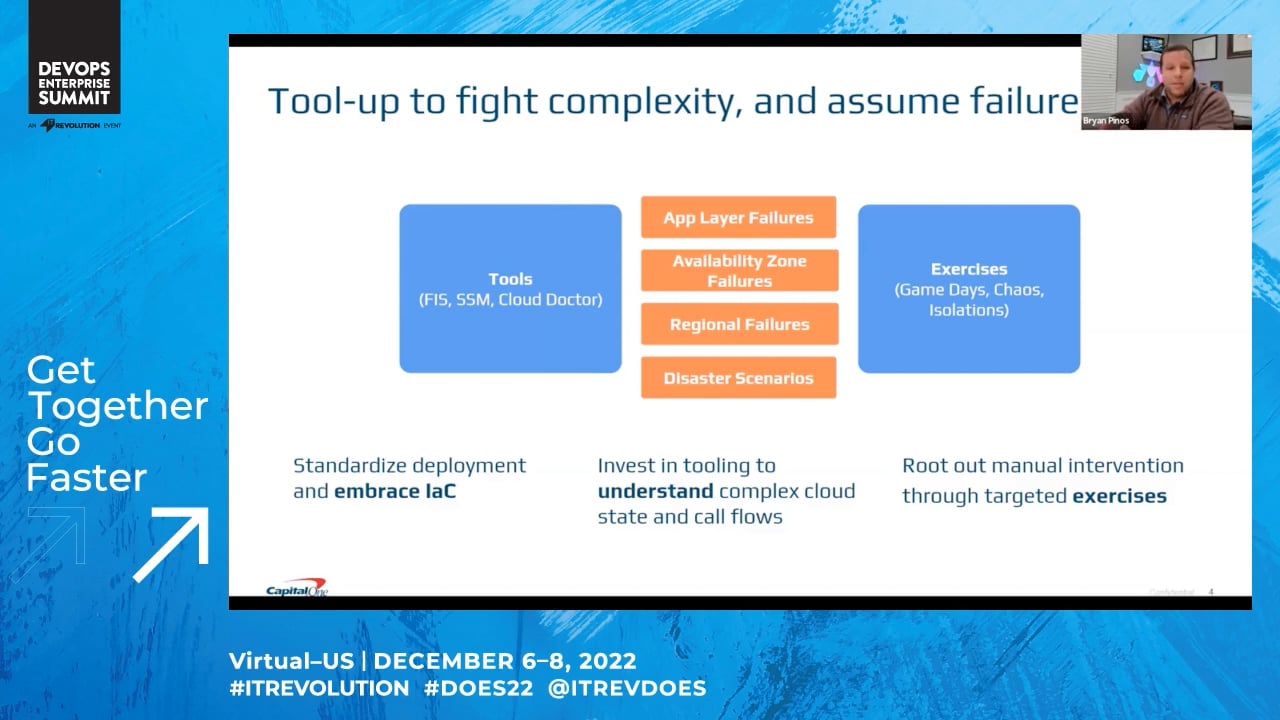
In the IT industry, testing in production has always been considered an anti-pattern. However, in Capital One we have been successfully testing our critical digital customer facing applications in production for over 18 months now! Why do we do it?
The answer is simple, the alternative to proactive chaos engineering is reactive crisis management.
Chaos engineering is not new to the industry or Capital One, what's new is the scale of experiments being executed on a regular basis and a set of closely integrated software solutions we are utilizing to make it successful.
BP
Bryan Pinos
Sr. Director, Software Engineering, Capital One
YS
Yar Savchenko
Director, Software Engineering, Capital One