Las Vegas 2022
ProdEx - Google's Production Excellence Program
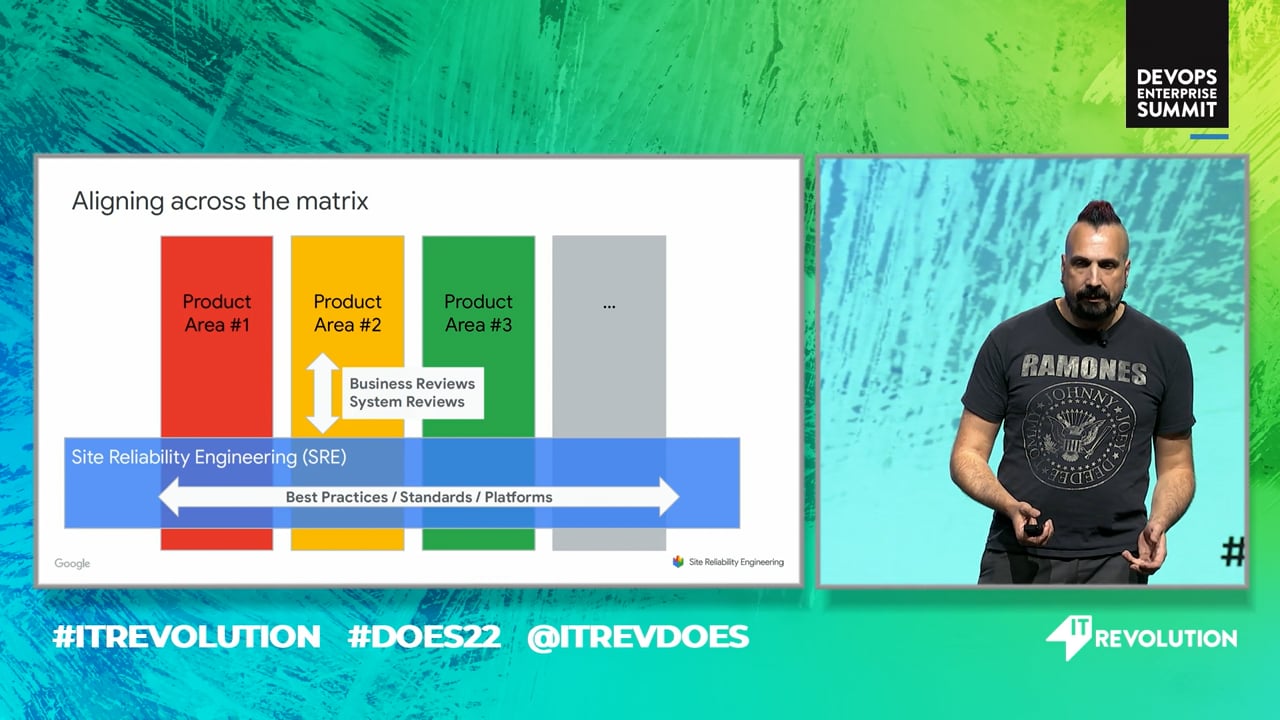
ProdEx is Google SRE's flagship program for production health and operational risk. It has been running for 7+ years across the SRE organization.SRE directors assess the health of SRE teams and provide coaching in an interactive review setting based on production metrics and business context.
CL
Christof Leng
SRE Engineering Lead, Google