Europe 2022
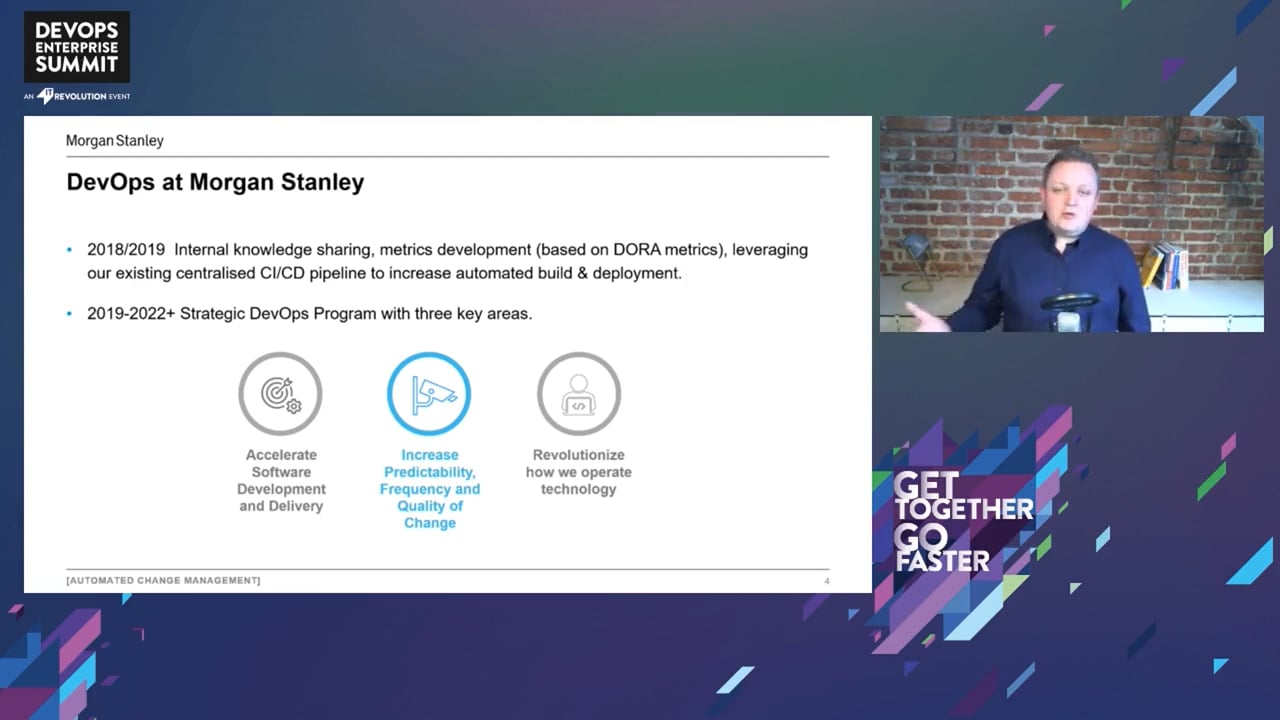
Automated Change Management
Automate the change management process by using development activities and data driven automated assessment of risk of making a change to production, such that changes were automatically approved, resulting in both better delivery outcomes and reduced risk of change implementation.
GP
Gus Paul
Executive Director Application Infrastructure, Morgan Stanley