US 2021
Tales From the Branches - Why GitOps Matters For Your Business Success
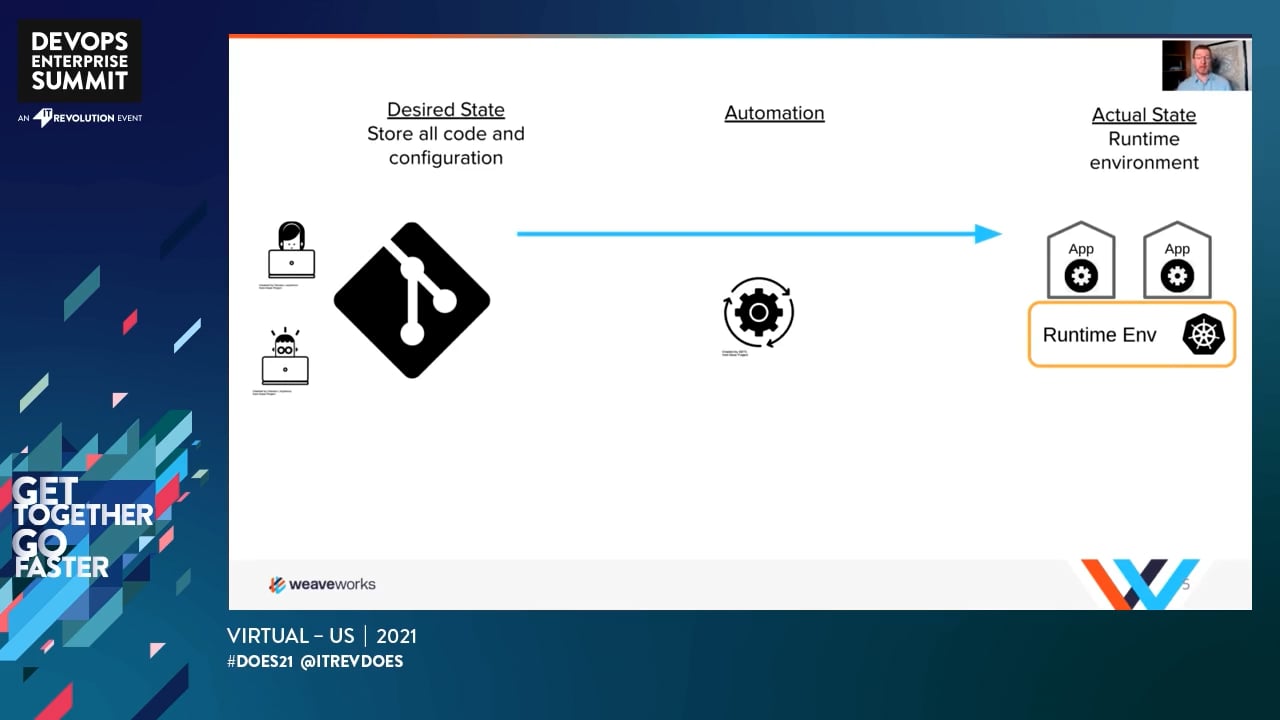
The pipeline-as-code approach allows git workflows to automate the deployment of CI/CD pipelines, turning code into features faster and at a more secure pace for business. And this is where GitOps gets interesting for your business.
The GitOps approach to continuous deployment, enables developers to focus only on developing and contributing code as they always have, through git repositories. Reconciliation loops in GitOps, monitor the actual versus desired state of your running software and align infrastructure automatically. Traditional operations teams can now evolve into SRE and DevOps roles that they aspire to with the introduction of DevOps in the first place. IT teams have now turned Kubernetes from a complex orchestration system to a platform that integrates all tasks and desired tools a modern cloud native enterprise needs. And GitOps is the essential pattern for the highly distributed and constantly changing environment that makes up the cloud.
In this session Steve will cover the key principles of GitOps, and demonstrate the real business benefits any size company can experience. He is tying GitOps practices back to the DORA IT metrics as measures of Software Delivery and Operational (SDO) performance including frequent deployments, shorter lead time, mean time to recover, and change failure rate. He will also show how these techniques provide solutions to a number of use cases including drift detection, malware remediation, disaster recovery and more.
This session is presented by Weaveworks.
SG
Steve George
COO, Weaveworks