US 2021
The Shift to a DevOps Model While Building Our Cloud Platform - You Build it, You Run it!
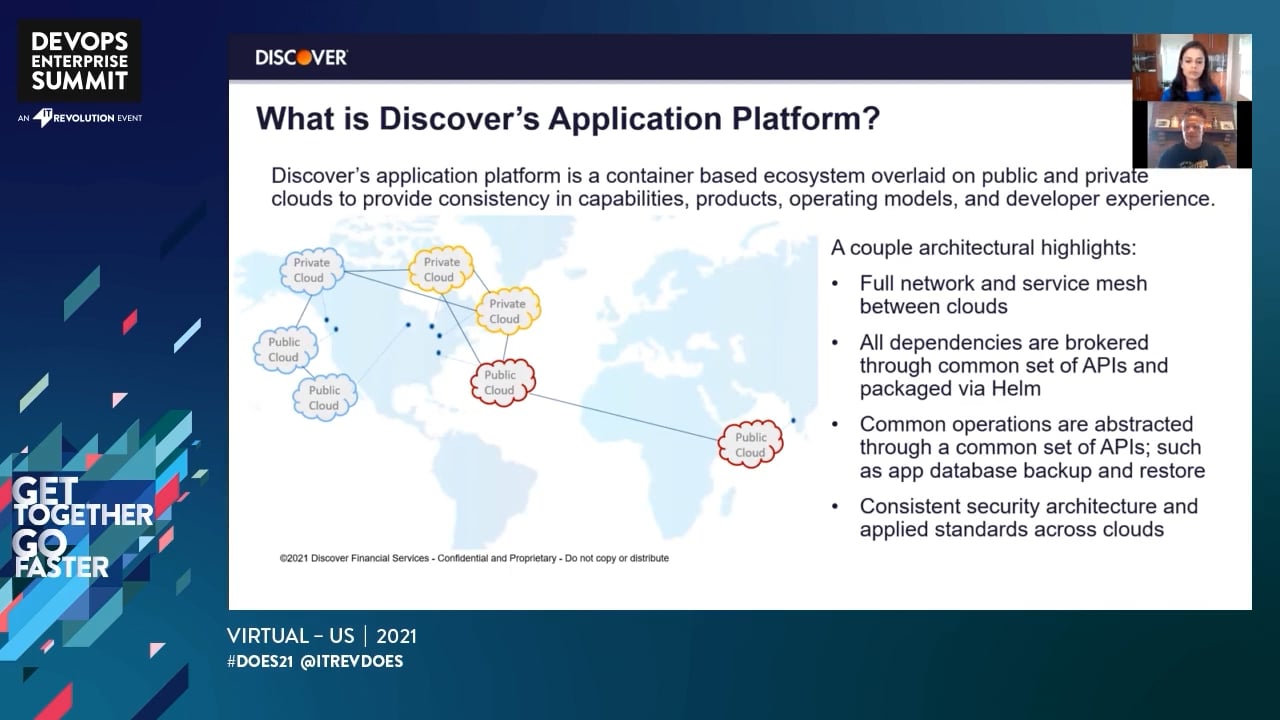
At Discover, we've built the next generation of container platform based on Red Hat's Open shift Container Platform which uses Kubernetes at its core orchestrator. This platform is the nucleus of a larger container ecosystem (a.k.a. "Tupperware"). Tupperware groups numerous products and services together to provide container builds and deployments, software defined networking, and brokered relational database, object store and caching public cloud commodity services. Discover’s multi-cloud architecture is centered on Tupperware’s cloud abstraction design and processes.
In this talk, we will share how we transformed our engineering practices from one that was silo’d to one that combined development and operations team into a DevOps team. Before DevOps was implemented, development and operation teams worked as two independent squads, each with its own goals and objectives. The differences and lack of communication between these teams often impacted the product, which in return affected the consumers of the platform and Discover. There was a lack of ownership, accountability and the lack of feedback loop from operations back into our product backlog was affecting us adversely.
We'll talk about techniques we used to drive the cultural transformation towards a DevOps oriented approach, practices that we followed and share what worked for us. We'll also cover the lessons learned through taking our teams around this DevOps transformation and the failures that we learned from. We'll discuss how we measured the efficacy of the transformation and our success criteria centered on consumer feedback and metrics like system uptime, number of incidents that caused production downtime, number of customer issues, etc.
This shift in approach helped improve our system uptime, improved our team ownership and accountability and resulted in fewer consumer complaints. We'll also cover how we leveraged trainings to upskill engineers and blameless postmortem analysis techniques to drive root cause analysis when “incidents” happened in production that caused outage. We’ll talk about our practice of Site Reliability Engineering and the focus on reliability which was central to our transformation. You'll walk away with an understanding of what it takes to truly transform the practices within your product team, embrace a true DevOps mindset and the benefits that this approach entails.
Throughout the transformation journey to shift our practices from one that was silo’d to a collaborative devops model, one of the key aspects we focused on was the culture of the organization. Our goal ultimately was to create better outcome for the consumers of the platform my offering improved reliability and better customer service. We created a set of teams that were self-organized and empowered to make the right decisions. We modeled this behavior within the teams by encouraging team members to make decisions for the scope of work they are responsible for and provide support as needed.
We recognized that mindset is everything when it comes to these transformations and new ways of working. We provided incentives in the form of “bravo” awards and recognition for team members to embrace the culture of “You build it, you run it” mindset. When “incidents” happened in production, we leveraged blameless postmortem analysis to drive for root cause analysis and take actions. To summarize, these are some of the key aspects of how we embraced culture as an enabler to the “You build it, You run it” mentality within our teams:
• Empowering team members
• Encouraging self-organization and decision making
• You Build it, You Run it: Mindset is everything
• Blameless Postmortem Analysis
SK
Sakthi Kasiramalingam
Director – Cloud Platforms, Discover Financial Services
BP
Bryan Payton
Senior Principal Enterprise Architect, Discover Financial Services