US 2021
Fear to Hope - How HCSC Became Nimble Through Experimentation During Peak Demand
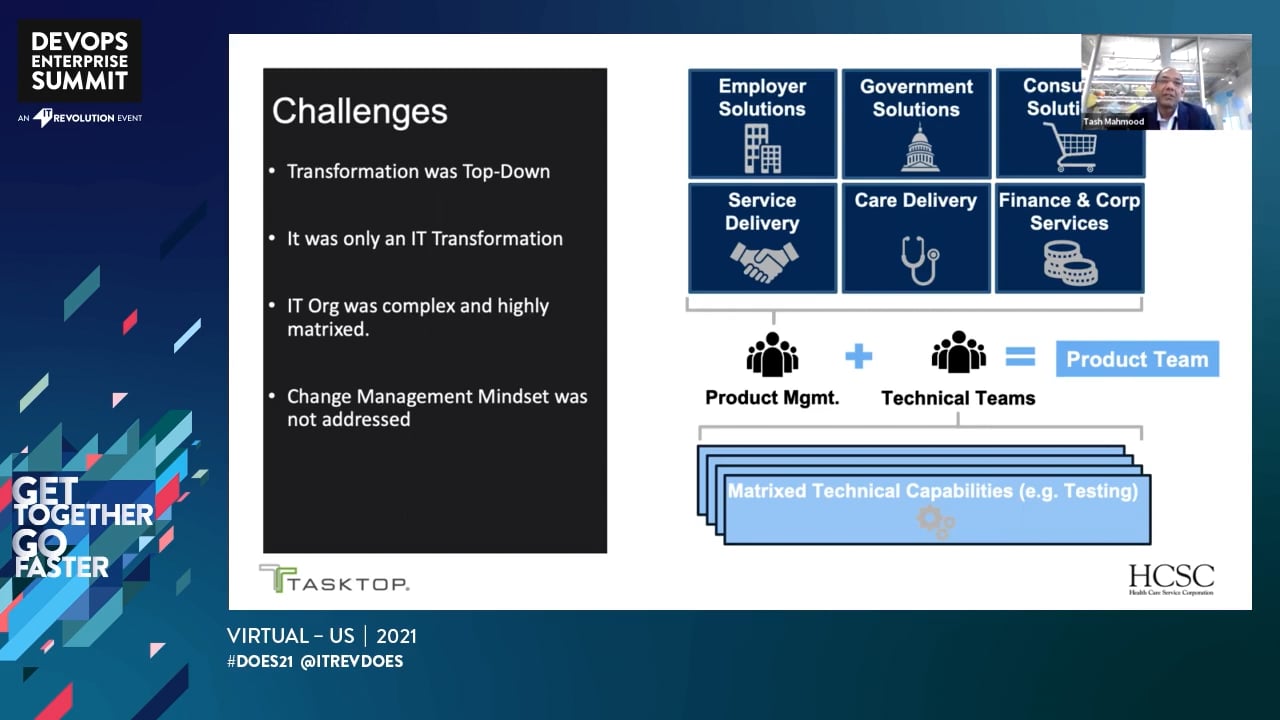
Does seasonal demand impact your ability to implement change? From insurance to retail to entertainment, peak demand can limit an organization's capacity to take advantage of one of the best times to run and learn from experimentation. In this talk, attendees will hear how one of the largest insurance companies in North America evolved to conduct experiments during their open enrollment season.
Focused on business results, HCSC teams addressed missing feedback loops in their delivery engine to be more responsive to insights gained from customer experiences. They addressed this feedback with fast experiments for delivering features, which made it easier and more compelling for customers to sign up for HCSC’s plans. From frozen to flowing, HCSC’s strategy set teams up to be nimble during peak season.
This session is presented by Tasktop.
TM
Tashfeen Mahmood
Senior Manager, DevOps, HCSC
DD
Dominica DeGrandis
Principal Flow Advisor, Tasktop