US 2021
DevOps SRE or ITIL – Know Before You Leap!
In an era of Continuous Integration, Continuous Delivery and Automation, implementation of a solid IT Service Management strategy is important for organizations to succeed at Digital Transformation. There are several IT Service Management Frameworks available today and the possibilities and processes stemming from each framework is often overwhelming. While all the Service Management methodologies are closely connected, we will discuss about the DevOps, SRE and the latest ITIL4.0 service management framework in how they compare with each other. What are the vision and values governing the frameworks and the guidance each provides when embarking onto this journey.
DevOps is an umbrella concept that advocates a collaborative working relationship between Development and Operations. It aims to achieve an adequate velocity of software and services for the line of business (i.e. high deploy rates) while simultaneously increasing the reliability, stability, resilience and security of the production environment.
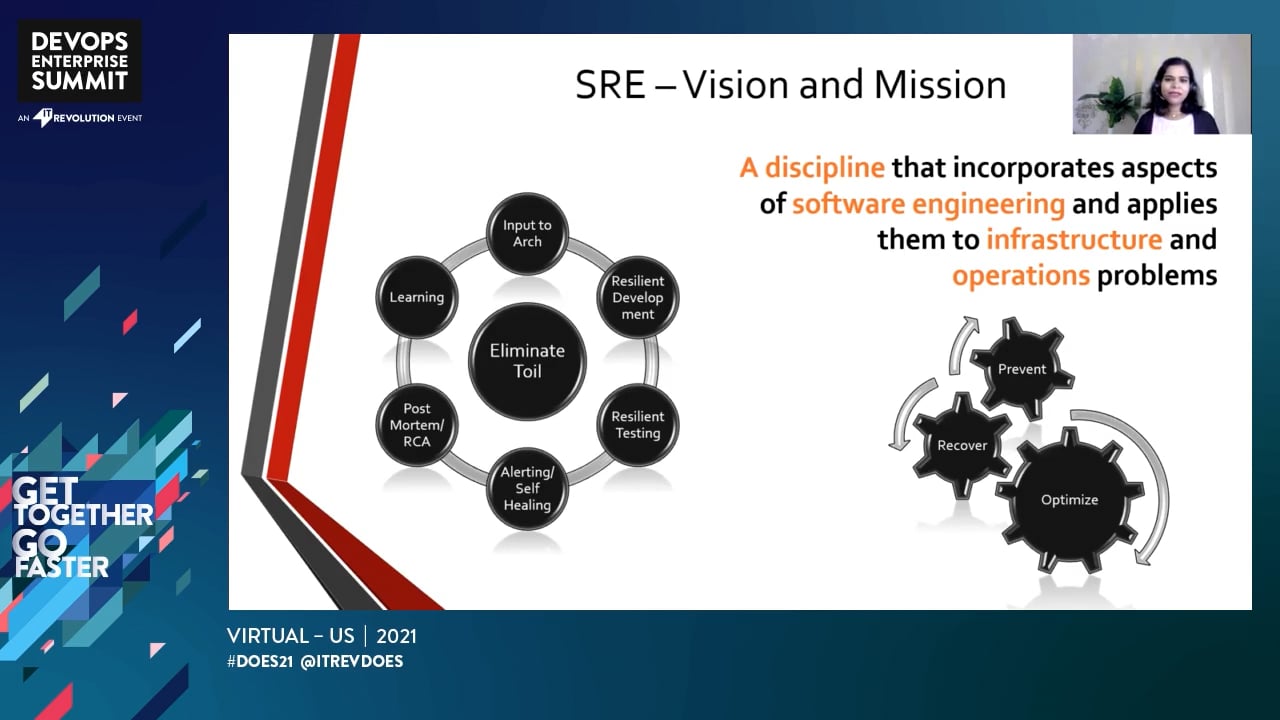
SRE or Site Reliability Engineering is Google’s approach to service management and emphasizes the development of systems and software that increases the reliability and performance of applications and services.
ITIL4 is the latest evolution of the well-known service management framework from Axelos. With the introduction of the new service value system to the core guiding principles of ITIL, it emphasizes service quality and consistency and aims for improved stakeholder satisfaction through ensuring value from the perspective of the stakeholders.
We will discuss on How can an organization decide which service management methodology to adopt to best enable them to deliver business value and to ensure a successful transformation powered with operational excellence.
All three methodologies can coexist together, however, adoption of DevOps or SRE or ITIL is as much a cultural and behavioral transformation for the organization and its people as it is about technological and process related changes. Organizations need to continuously adapt and adopt, upskill and upscale to keep up the pace in the continuously evolving digital world.
MM
Meenal Meenaakshi
Product Landscape Owner, SAP