US 2021
Got Score? Scaling DevOps Adoption
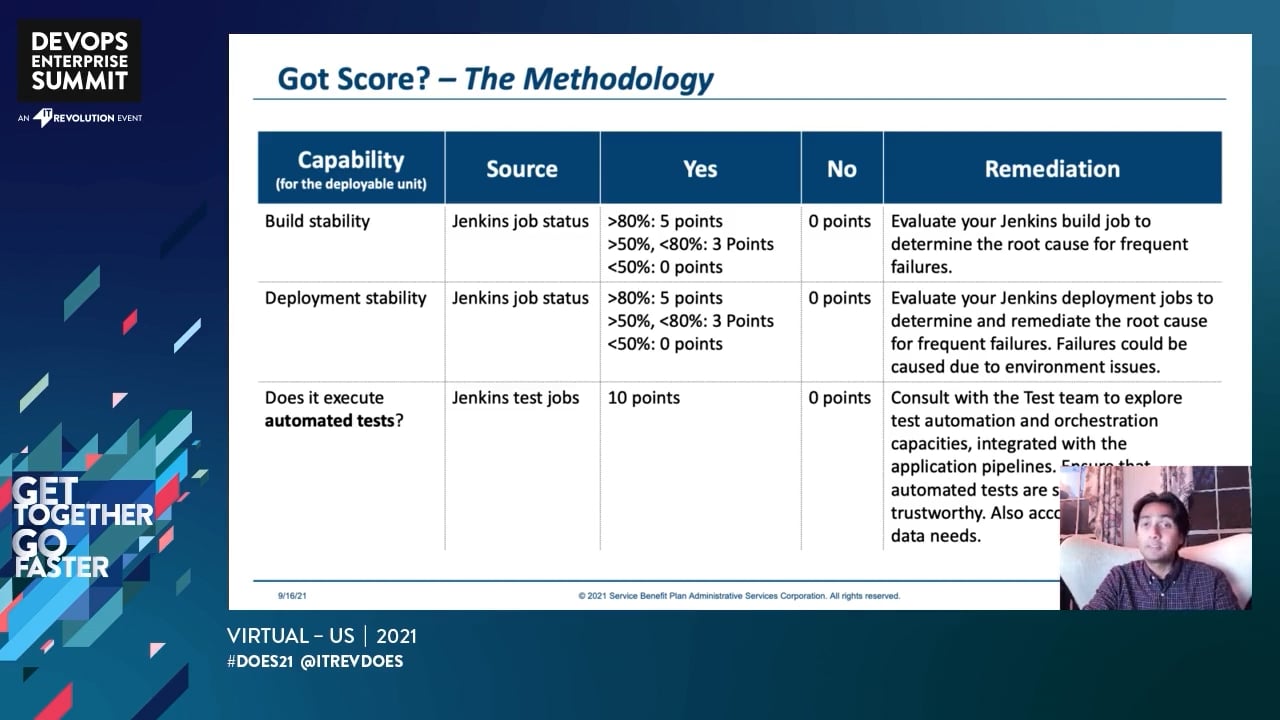
• The usage of your DevOps tools tell a story
• Elicit this story to identify insights
• Present these insights into opportunities for improvement
• Finally, wrap these opportunities into initiatives and gamify adoption
We started our journey in 2016 intending to reduce wait times and manually-intensive, error-prone, repetitive handoffs across different departments. To accomplish this, we branched into a 'Center of Excellence'. Tasked with supporting up to 6 LoBs, each having multi-year, multi-million dollar initiatives, we designed the DevOps CoE with various arms - one tasked with Platform Engineering, while the other for Adoption, while still another for exploring emerging technologies. With support at all levels, we also were able to conceive various forums to generate grassroots enthusiasm while strategically employing some top-down levers to ensure, subtly, that everyone had some skin in the DevOps adoption ‘game’.
And our entire adoption approach is extensively centered around metrics.
We elicited data from our platform, wrapped these into many insights, packaged these insights into initiatives and are now well on our way in 'moving the needle' - on a near-real time basis - all the while, while having fun doing it. And in doing so, we’re leading the way for other business functions to follow, and adopt the ‘data-driven’ way of thinking.
RS
Rajat Sud
Principal Engineer and DevOps Evangelist, CareFirst
DA
Don Almeida
Manager, DevOps COE, CareFirst