US 2021
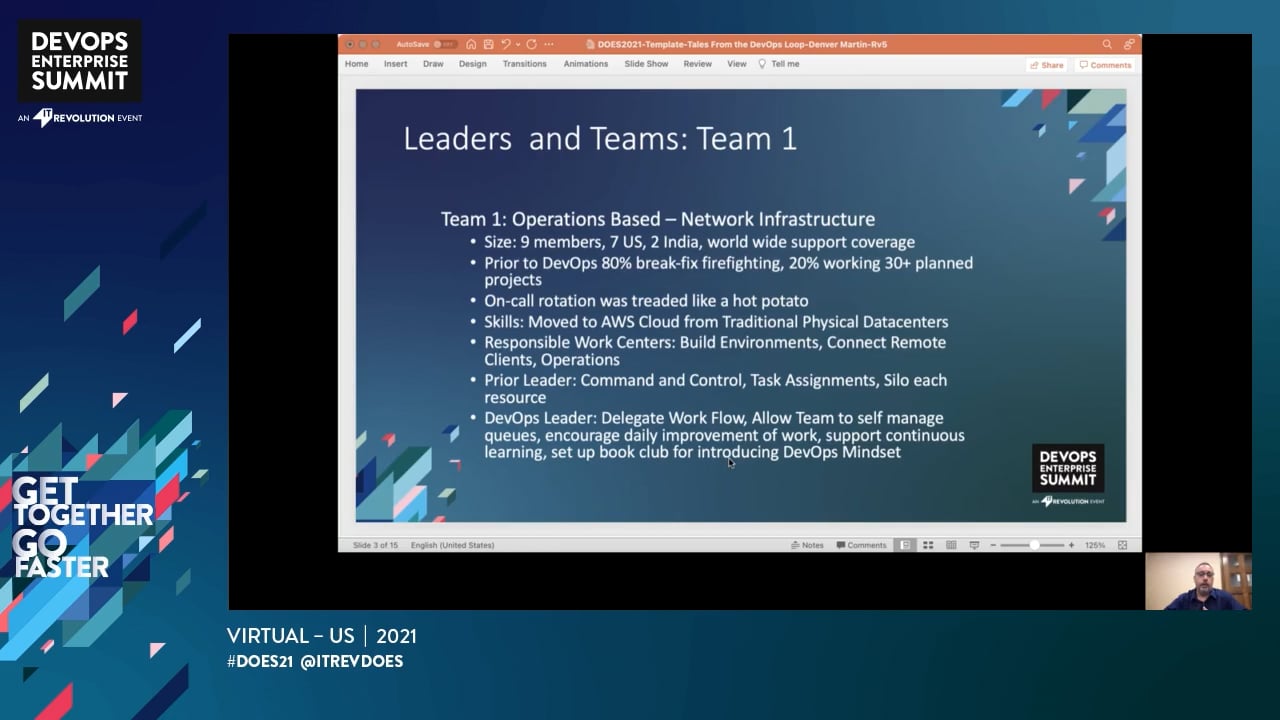
Tales From the DevOps Loop: 4 Teams Approach to 1 Common DevOps Framework
Denver has been working in IT since 1998 and has a Masters of Information Technology and an MBA in global technology management. He is currently enrolled in an Executive Doctorate in Business Administration program at Crummer Graduate School of Business, Rollins College in Winter Park, FL, dissertation topic includes DevOps. Denver has been teaching at various colleges and universities since 2001 as an Adjunct Professor of IT, currently teaching with Purdue University Global.
He is the Director of DevSecOps for Thread Research, a leading provider of Distributed Clinical Trials for Pharmaceutical and Medical Devices. Denver has held many roles in the IT industry, mostly in operations and support. He started his journey into DevOps in 2017 when his team read The Phoenix Project as a team book club. He has since led efforts at 3 companies with successful transition into adopting the DevOps mindset and moving them into a DevOps model and framework.
DM
Denver Martin
Director of DevSecOps, Thread Research