US 2021
SRE From Scratch: An Enterprise Journey
This session describes our journey of transformation at a large European Telco to SRE – starting from a traditional set up of having a Platform Development team, a support team, and teams that utilized the platform to onboard users and applications onto the Platform.
In the traditional setup, no one team was really happy, with the symptoms:
- Our version of “works on my machine” and “well, doesn’t on mine!” conversations
- Ownership of the availability and resilience of the platform
Our journey started with a diktat from leadership on SRE adoption. How do we make SRE happen from a blank slate?
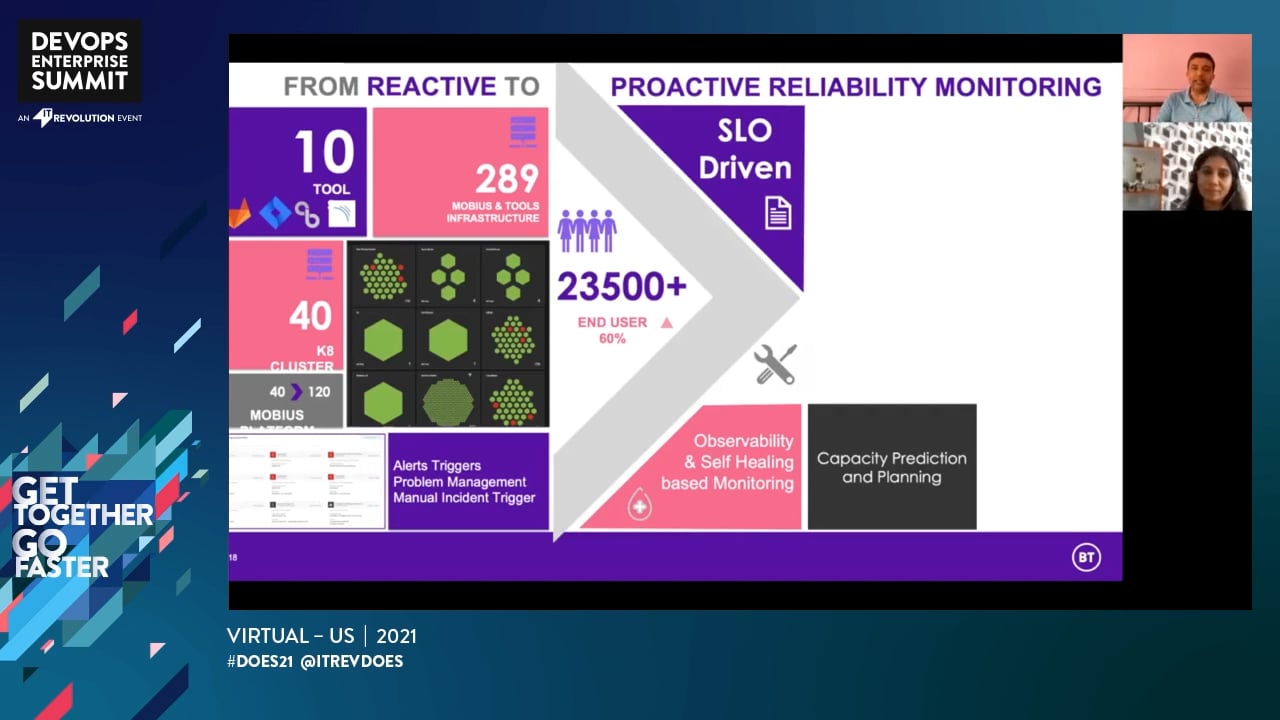
Same place as most people start off – we pulled the Google books and the DOI SRE certifications. Obviously (we thought), we had to set our SLOs; everything flows from there.
But how do you set a SLO if you don’t know the capability of the current system?
Since it was meaningless to set SLOs without a baseline, we starting defining and then instrumenting our baseline. Once we had the instrumentation in place, we then started building on it to define our Services, coverage, and observability.
Along the way, we’ll also share our tools and processes experiences, what worked and what didn’t, and overall a great overview of what it takes to establish SRE in a large traditional setup.
MG
Monika Gupta
SRE & Support Lead - MOBIUS Platform & Tools, British Telecom
AR
Avinash Rao
VP of Products, Digite