Europe 2021
Staying Out of the (Bad) Headlines: Keeping Attackers Out of your DevOps Toolchain
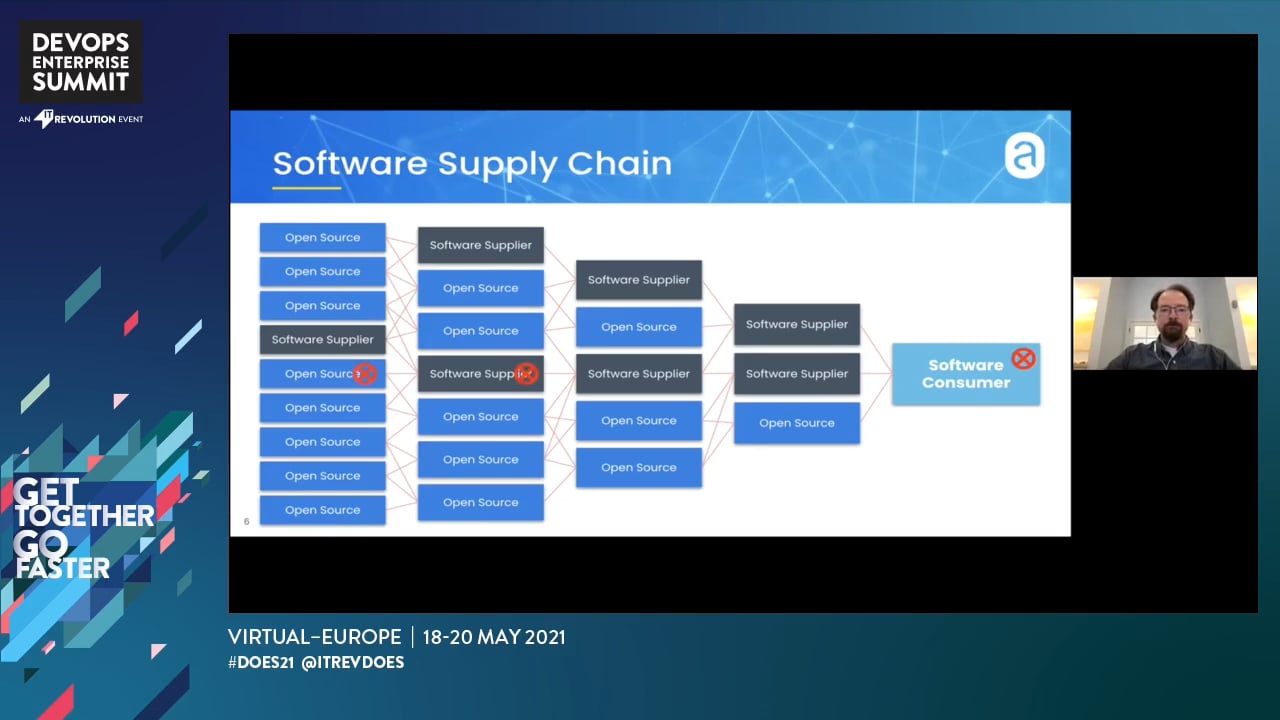
DevOps lets developers innovate faster. But some normal DevOps processes can create the opportunity for bad actors or dangerous code to enter your DevOps toolchains and your software applications. Where are the security risks and how can DevOps teams prevent attacks without slowing down delivery? We’ll provide some easy tips and best practices to secure your toolchain while keeping your development moving.
This session is presented by Anchore.
DN
Daniel Nurmi
CTO & Co-Founder, Anchore
PN
Paul Novarese
Senior Solutions Architect, Anchore