Europe 2021
A Layered Approach to Progressive Delivery
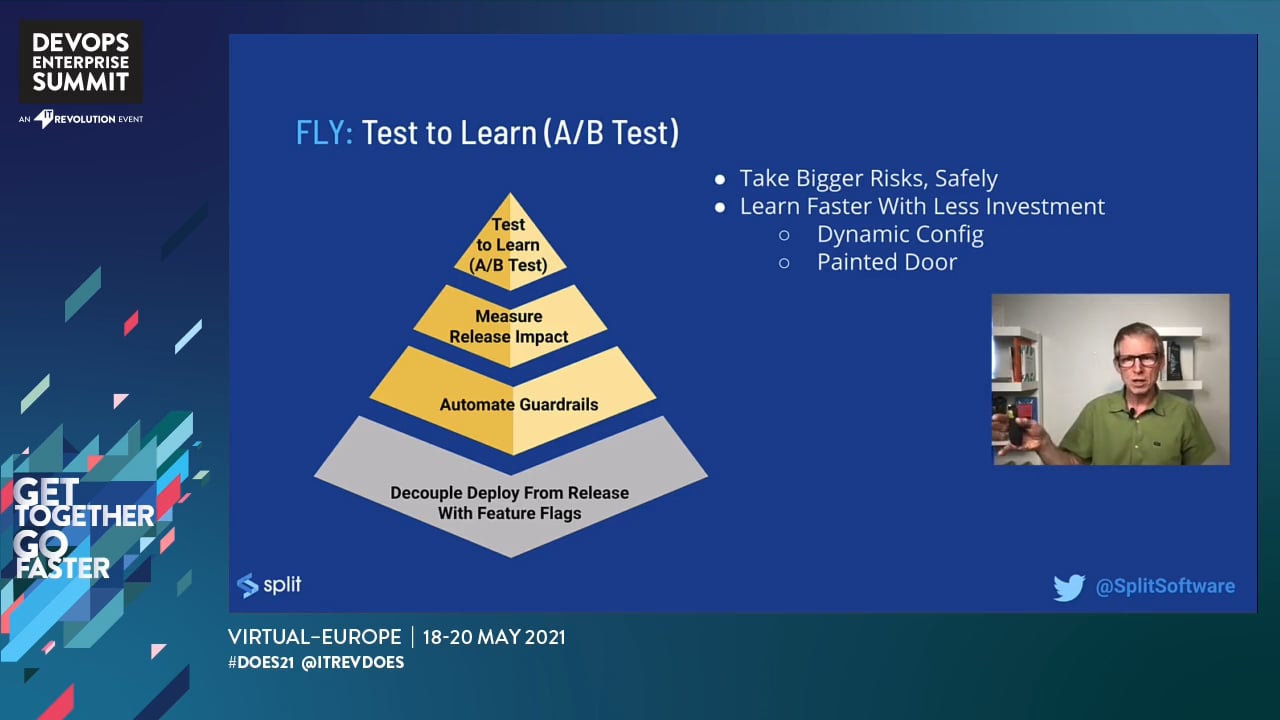
Progressive Delivery is the practice of decoupling deploy from release, allowing changes to be safely pushed all the way to production and verified there before releasing to users. Selectively dialing up and down the exposure of code in production without a new deploy, rollback, or hotfix is the foundation of Progressive Delivery, but the higher-level benefits of safety and fast feedback come from layering practices on top of that. Whether you are new to Progressive Delivery or are already practicing some aspect of it, you'll learn/refresh on the basics and then come away with a powerful model for layering higher-value benefits on top of that foundation.
This session is presented by Split.
DK
Dave Karow
CD Evangelist, Split