Europe 2021
Industrializing your Data Science Capabilities
Data Science and AI are huge buzzwords nowadays. Data Scientists are creating insights and predictions with huge potential to overthrow our daily work by far. Unfortunately many of these approaches keep stuck after few meters in the mud of operations.
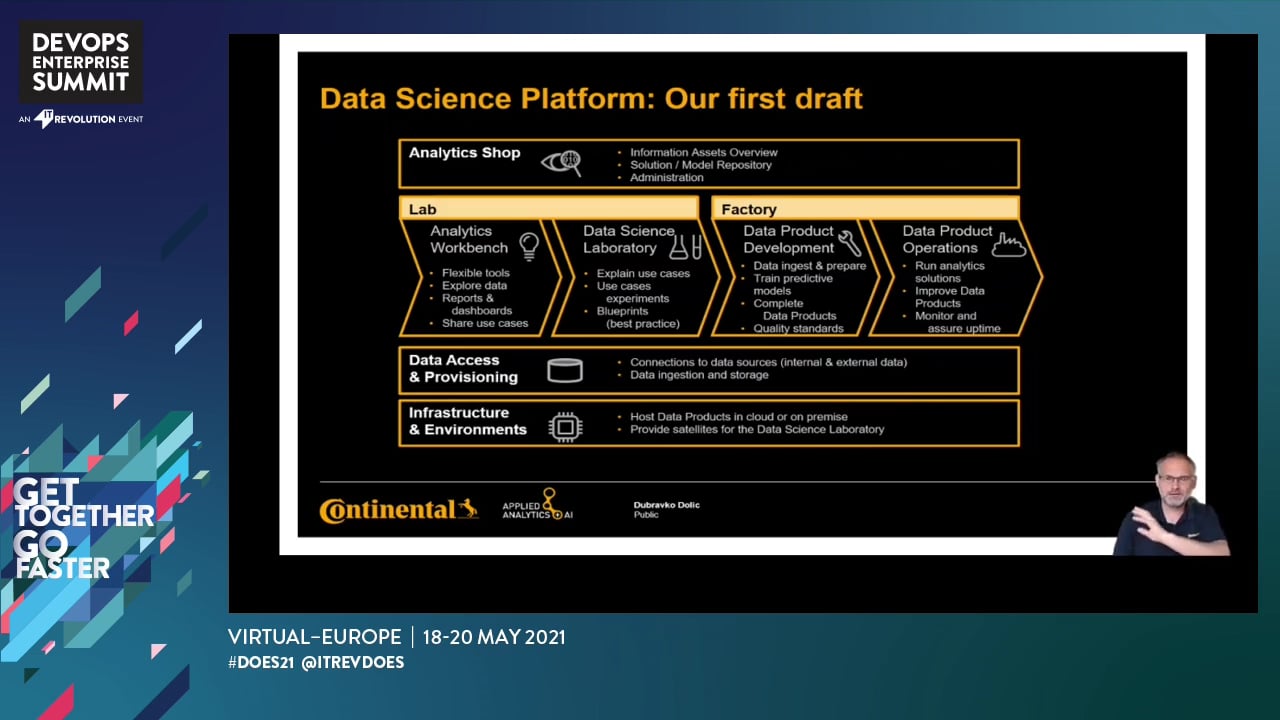
At Continental Tires we started out by creating an environment and accompanying processes from day one. Following the agile approach of Continous delivery and Continous deployment the Data Science Factory was a supporting infrastructure to support Data Scientist to industrialize AI and Machine Learning Use Cases. Today this environments is used by Data Scientists all over the different parts of Conti Tires and is even highly recognized by players like AWS, Microsoft or Google.
In this talk we will present the architecture and the approach we followed to implement this provider-independent environment. Done as Infrastructure-as-code and aligned with processes to follow a CI/CD pipeline Data Science at Tires can be done for developing real products inhouse. DevOps and MLOps are collaborating together with the Data Scientists to bring the old industrial company into the new world of Software and Data driven products.
DD
Dubravko Dolic
Head of Advanced Analytics & AI, Competence Center eCommerce, Fleet Solutions & Data Science, Continental Tires