Europe 2021
Scaling Data Analytics Delivery Model With DevOps Practices
As a Data-Driven company, adidas has strong demand for reliable, scalable and fast Data Analytics Platform.
This presentation is about our solution how we enabled DevOps principles along with number of capabilities from the Accelerate book (like Continuous Delivery, Architecture for scaling) in the Data Warehouse domain. During the journey we convinced more than 10 teams around the world how DevOps principles bring them speed, high quality and empowerment in creation of data models and data pipelines.
Now as the practices are adopted, 10+ teams are delivering Data for Analytics demands:
- independently from each other
- faster and with higher quality
- in smaller batches
- deploying changes to complex data models and pipelines on-demand multiple times a day instead of old fixed biweekly cycle.
Some details:
- Our purpose is to increase speed and quality in delivering Data for Analytics use cases by:
- Increase quality of delivery in Data Warehouse environments
- Increase speed of changes
- Improve reliability of complex Data Models and Data Pipelines
- Improve reliability of deployments
Top challenges:
- Merging skills and ways of working of experts coming from Data Warehousing and Software Engineering backgrounds
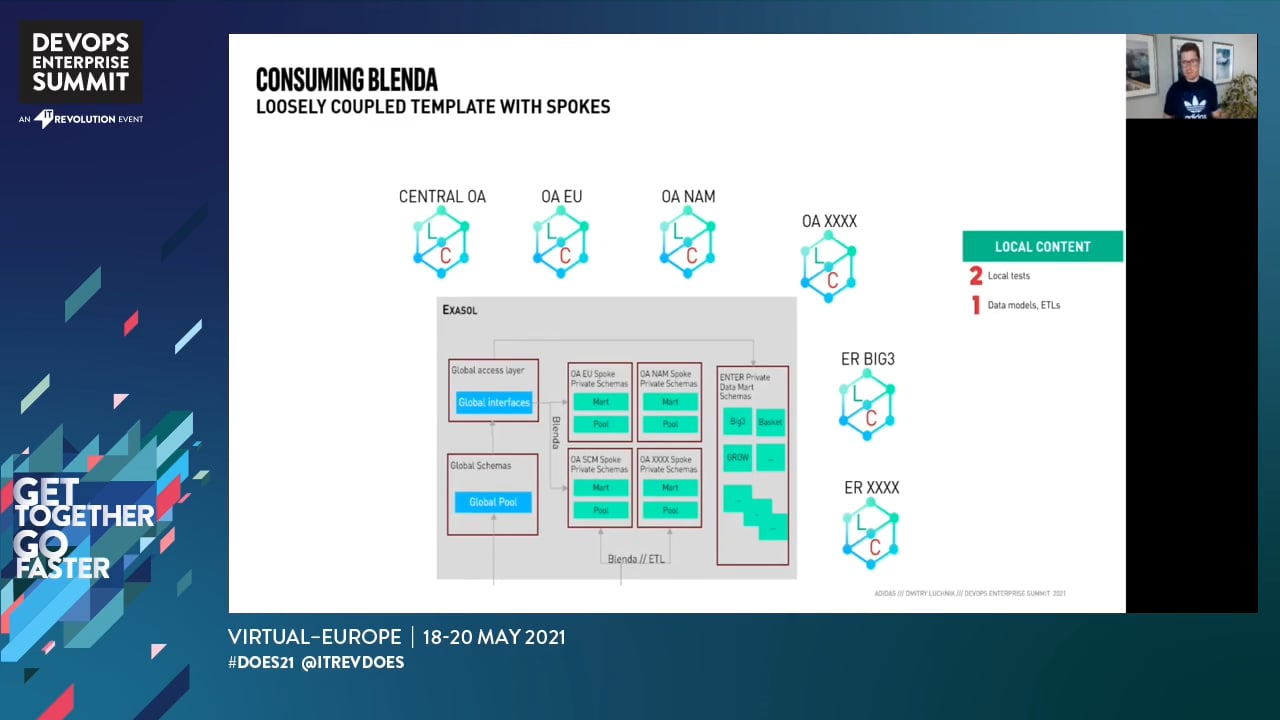
- Finding Continuous Integration and Delivery patterns acceptable for Data models and pipelines
- Some tools in Data stack cannot be managed with the code
- Code (definition of the Database object) is tightly coupled with the data
- High complexity of atomic objects (e.g. a database view harmonizing KPI calculation from data points from multiple systems can contain several thousands lines of code)
DL
Dmitry Luchnik
Director Data Analytics Architecture, adidas