Europe 2021
Trials and Tribulations of a DevOps Transformation in a Large Company
Every organisation faces different problems when transitioning to a DevOps focused culture and large organisations can present more challenges than most. In this case study, I’ll share our experiences of how we put DevOps Theory into practice in a 3500-developer organisation; what worked for us, what didn’t work and the areas we are still working on 2.5 years into the transformation.
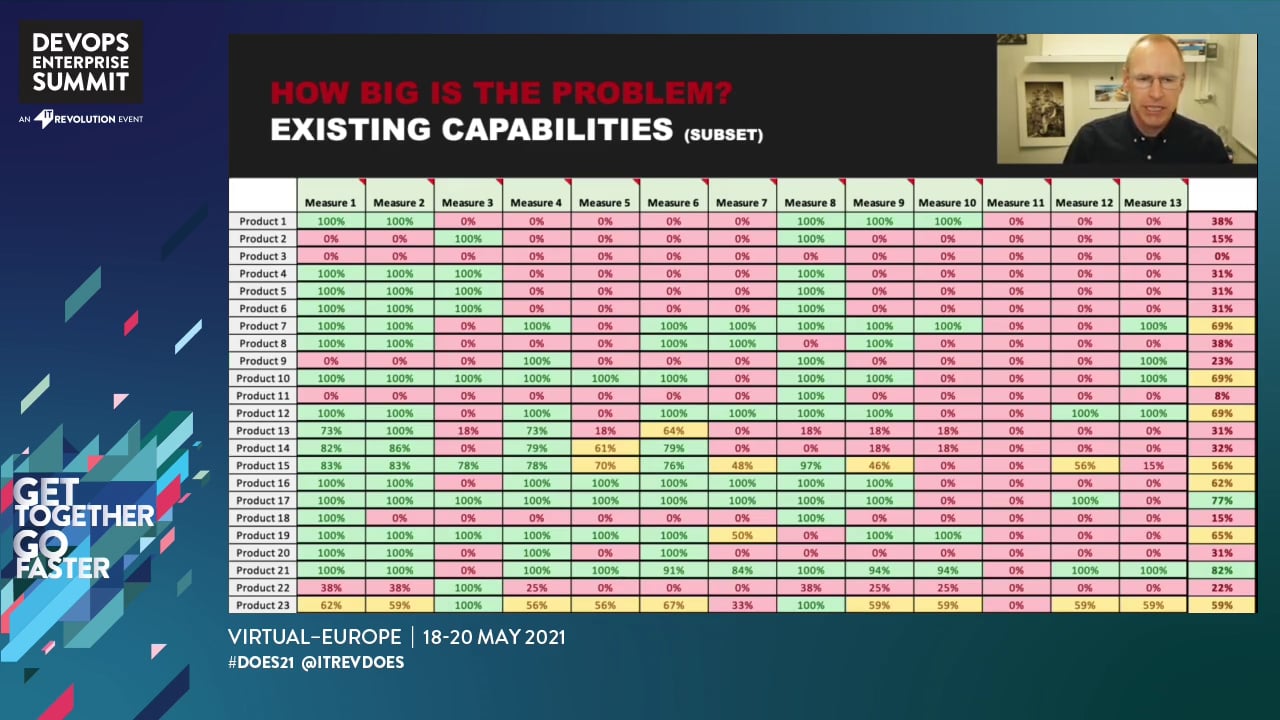
Through automation, we standardised CICD pipeline creation, which saved each team weeks of effort per pipeline. Automation enabled teams to take full advantage of the built in DevOps capabilities such as Shift Left on Security and Continuous Integration. Extending the automation into custom dashboards enabled teams to visualise their progress towards Continuous Delivery and take action where appropriate.
AN
Ashley Noble
Engineering Fellow, Honeywell