Las Vegas 2018
Have Your Cake and Eat It: VMWare IT Adoption of PKS
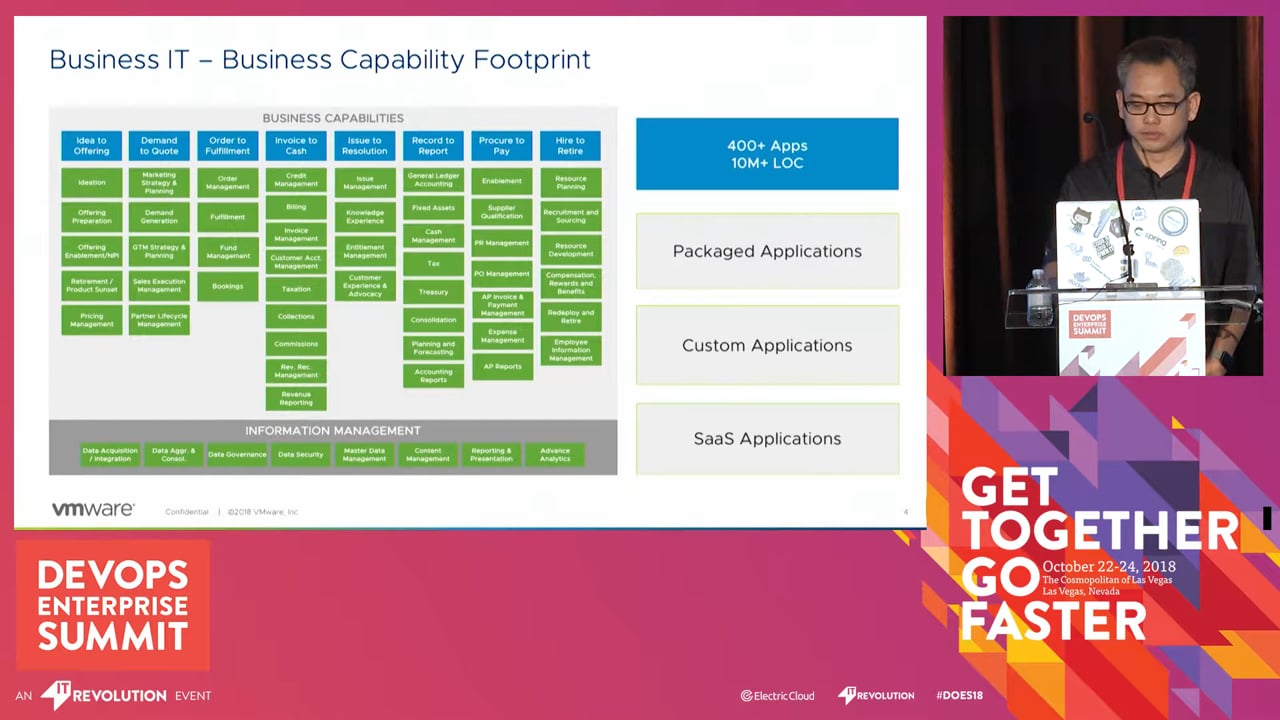
VMware IT has been on the journey with containers for more than two years with over 4,000 containers running. Having gone through the various container orchestration framework, from hand-rolling ones to proprietary ones, the team found that orchestration was limiting the ability to broadly adopt the container technology. With Kubernetes established as the de facto container orchestration platform standard, VMware IT adopted it as the go-forward container platform.
In this session, you will discover how VMware IT super-charged the container adoption with all the benefits Kubernetes brings to the container workload by deploying Pivotal Container Service (PKS) with VMware NSX-T integration instead of vanilla Kubernetes.
You can have your cake and eat it too.
Eric Rong leads the strategy and architecture of the next-gen Cloud Native Platform and application transformation for VMware Business IT. He has worked on architecture for various business areas within VMware IT to support Marketing, Sales to Support. Prior to VMware Eric worked at Franklin Templeton Investment as technical consultant in web technology. Eric has 20 years of industry experience in complex IT application delivery.
ER
Eric Rong
Technical Architect, VM Ware