San Francisco 2017
DevOps at Scale is a Hard Problem
You join a company with 3000+ engineers; you interview a ton of them; understand their pain points -- sound familiar? Well, this was what my early days at Yahoo looked like back in 2014. The most common response I got, “I wish there were fewer barriers”. The barriers made it hard for engineers to freely express themselves through the products they built.
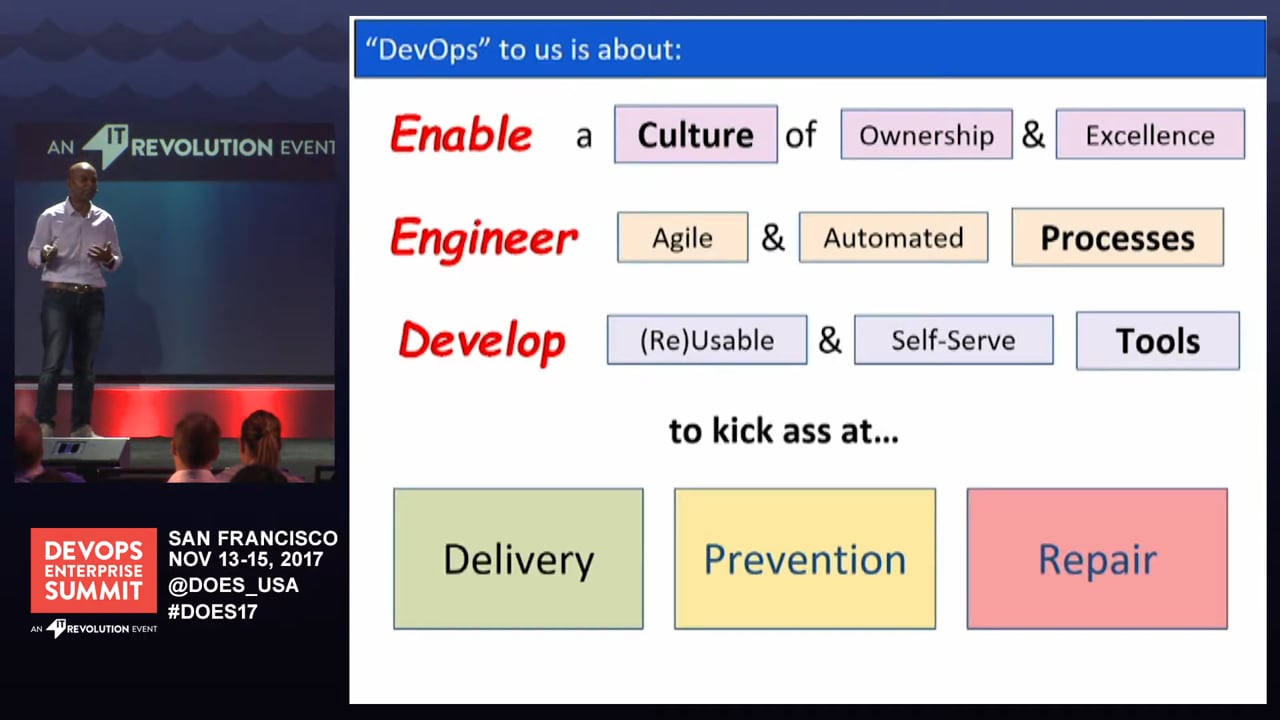
Attempting to solve this, I join forces with a colleague of mine (Shay Holmes). We set out on a mission, a pretty long one, to try and remove most of the barriers using software. The macro goal? Velocity! Agility! Step #1: come up with something that we could use as a reference for our (DevOps) transformation. So, we came up with a nice slide deck; did multiple talks, road shows, blog posts, and much more, to campaign our mission.
We thought we were doing great up until the time came where we had to start executing. And, yes, we hit roadblocks; multiple roadblocks.
First, we attempted to route alerts directly to the team who had the best chance of fixing a production issue, essentially bypassing 3 layers, to lower TTR and TTD. This also enables a culture of ownership (you wrote it; you own it), and creates the right incentives to keep monitoring clean. But, turns out, this was a rather hard problem to solve (and not fully solved yet).
Second, we try to get teams to continuously deploy software to production. Fortunately, most of Yahoo was already doing CD as it had been a corporate goal for like a year. But, there was a problem: few teams were trying to work around the automated CD requirements by having manual QA approval. The reality was those teams were trying to merely meet the requirement of goal (which, btw, is not bad in itself); not its spirit. How do you overcome something like that? (when it was agreed upon as a best practice)
Third, we try to treat operations as an engineering discipline and invest in solving (production) problems using software and automation. But, building an intelligent, event-driven, auto-remediation framework needs investment, and most teams were already pretty buried in tech debt and barely making any forward progress. How do you dig yourself out of this hole? How do you convince teams to automate themselves out of their jobs?
Fourth, we made a big push for AWS; we came up with multiple use cases that made sense. Made good progress on some; not so much on others. Some of the challenges we faced included cost (can get expensive real quick); security (securing our users and data is non-negotiable); this also requires a ton of investment, especially at the foundational services layer, to make it feasible at scale. Given the enormous challenges, how do you make forward progress?
I will dig deeper into each of these during the talk; give insights into what worked, what didn't, and the lessons learned. It should be a productive session.
Kishore Jalleda, Sr. Director, Production Engineering, Yahoo, Inc
KJ
Kishore Jalleda
Sr. Director, Production Engineering, Yahoo, Inc