Las Vegas 2018
DevOps for AI
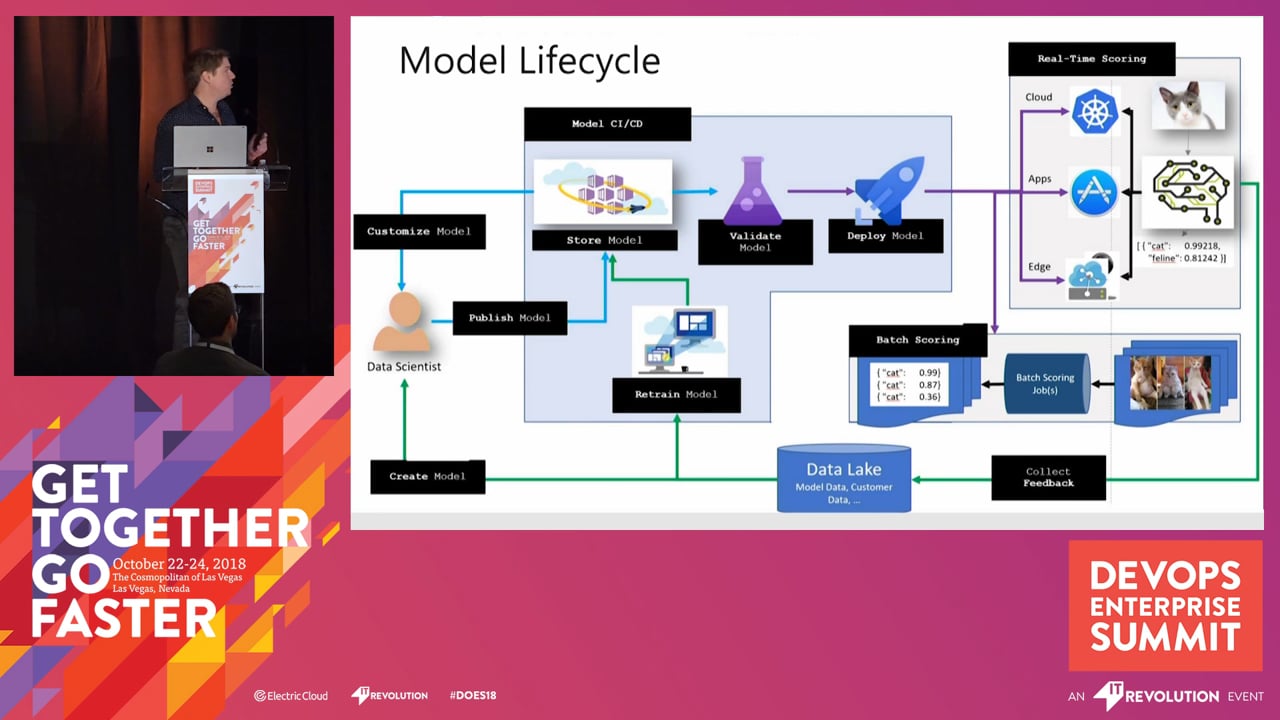
Because the AI field is young compared to traditional software development, best practices and solutions around life cycle management for these AI systems have yet to solidify. This talk will discuss how we did this at Microsoft in different departments (one of them being Bing).
Gabrielle Davelaar is a Data Platform Solution Architect specialized in Artificial Intelligence solutions at Microsoft. She was originally trained as a computational neuroscientist. Currently she helps Microsoft’s top 15 Fortune 500 customers build trustworthy and scalable platforms able to create the next generation of A.I. applications.
While helping customers with their digital A.I. transformation, she started working with engineering to tackle one key issue: A.I. maturity. The demand for this work is high, and Gabrielle is now working on bringing together the right people to create a full offering.
Her aspirations are to be a technical leader in the healthcare digital transformation. Empowering people to find new treatments using A.I. while insuring privacy and taking data governance in consideration.
Jordan Edwards is a Senior Program Manager on the Azure AI Platform team. He has worked on a number of highly performant, globally distributed systems across Bing, Cortana and Microsoft Advertising and is currently working on CI/CD experiences for the next generation of Azure Machine Learning.
Jordan has been a key driver of dev-ops modernization in AI+R, including but not limited to: moving to Git, moving the organization at large to CI/CD, packaging and build language modernization, movement from monolithic services to microservice platforms and driving for a culture of friction free devOps and flexible engineering culture.
His passion is to continue driving Microsoft towards a culture which enables our engineering talent to do and achieve more.
GD
Gabrielle Davelaar
Data Platform Solution Architect/A.I., Microsoft
JE
Jordan Edwards
Senior Program Manager, Microsoft