Las Vegas 2019
Shaping the Cloud - How We Transformed FINRA With DevOps
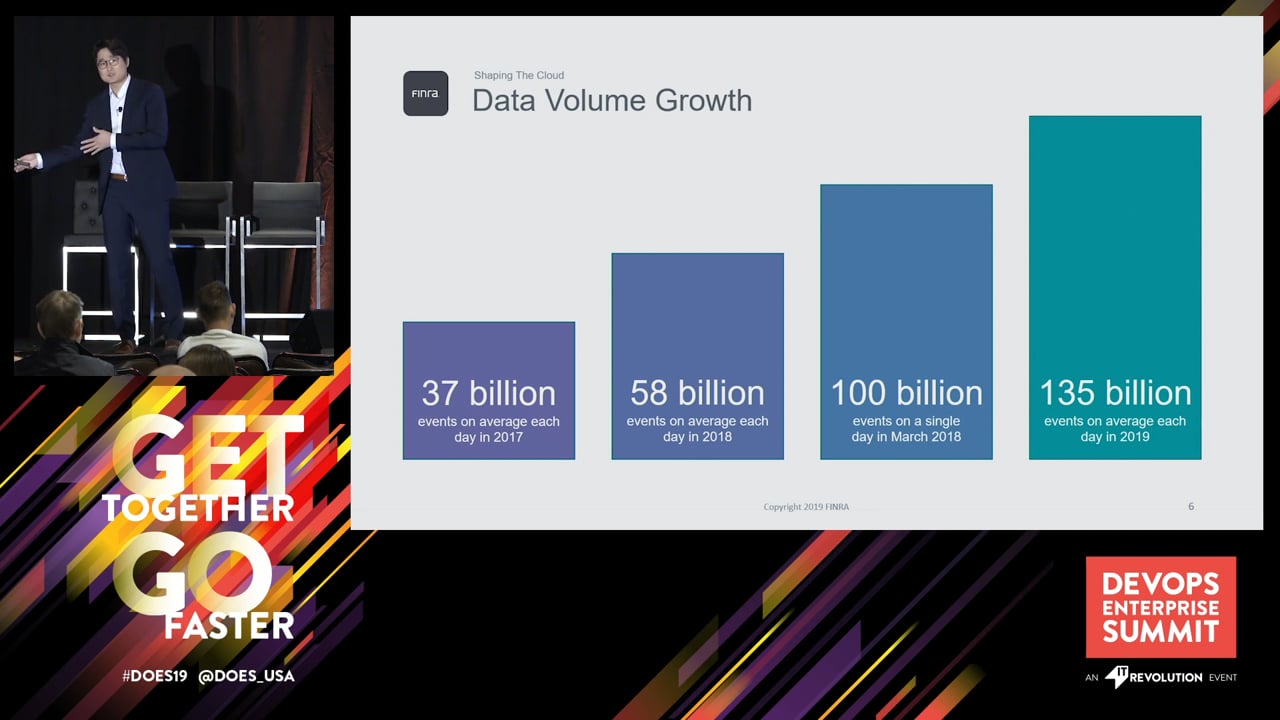
FINRA regulates the US broker-dealer industry and monitors market/exchanges daily, processing up to 135 billion transactions per day. Given its massive amount of data processing needs and 30+ petabytes of data storage, it was necessary for FINRA to rely on cloud computing and services to ultimately meet the regulatory demand. However, it was not an easy task to migrate the systems to the cloud due to the regulatory environment, compliance needs, audit requirements, security risks, and so forth. On top of that, culture change was an absolute must to shift from the traditional data center mindset to the public cloud world.
DevOps transformation was a key to success in migrating the entire portfolio of applications to AWS. The transformation involved organizational structure changes, introduction of new tools/concepts, continual education, and rapid refinements. So how exactly can you achieve this transformation for your organization?
In this session, Daniel Koo will speak about FINRA's DevOps journey, how it started and how it evolved throughout the past 3-4 years. The talk will highlight the organizational structure/transformation that worked, provide a walkthrough of the DevOps toolchain (custom tools, Open Source, SaaS) supporting from project inception to delivery/operations, as well as the successful bootcamp training implemented and conducted across 1000+ technologists. Additionally, it will outline how you can measure DevOps maturity to support sustainment and continuous improvement.
DK
Daniel Koo
DevOps Products & Engineering, FINRA