Las Vegas 2020
How to Crush Major Incidents with DevOps Agility
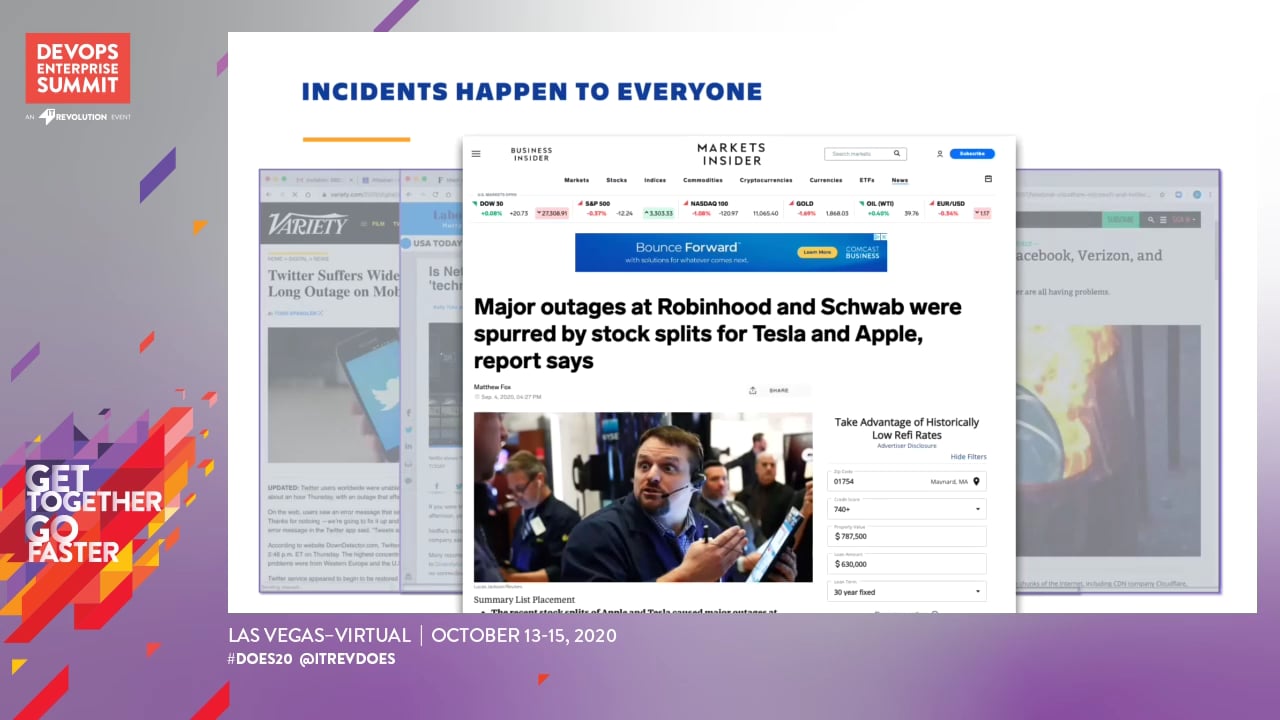
The key to DevOps success is being prepared for incidents, responding quickly and ultimately getting services back up and running. In this session, we’ll explore how, using Atlassian tools, Dev and Ops teams can work together to do just that: respond quickly to incidents, troubleshoot their cause and restore services as fast as possible. We’ll also take a close look at how teams are improving communication and collaboration across their entire organization, minimizing the business impact of unplanned service disruptions.
Darren leads the product marketing team for Atlassian’s ITSM and ITOM Products. He previously held executive positions at Opsgenie, Onshape, InVue, and DS SolidWorks and has a passion for exceptional technology. He enjoys spending time with family, camping, and more recently, woodworking. Darren holds a degree in mechanical engineering from the University of Florida.
This session is presented by Atlassian.
DH
Darren Henry
Head of Product Marketing, ITSM & ITOM, Atlassian