Las Vegas 2020
Optimizing at Scale: Using ML to Optimize All Applications Across the Service Delivery Platform
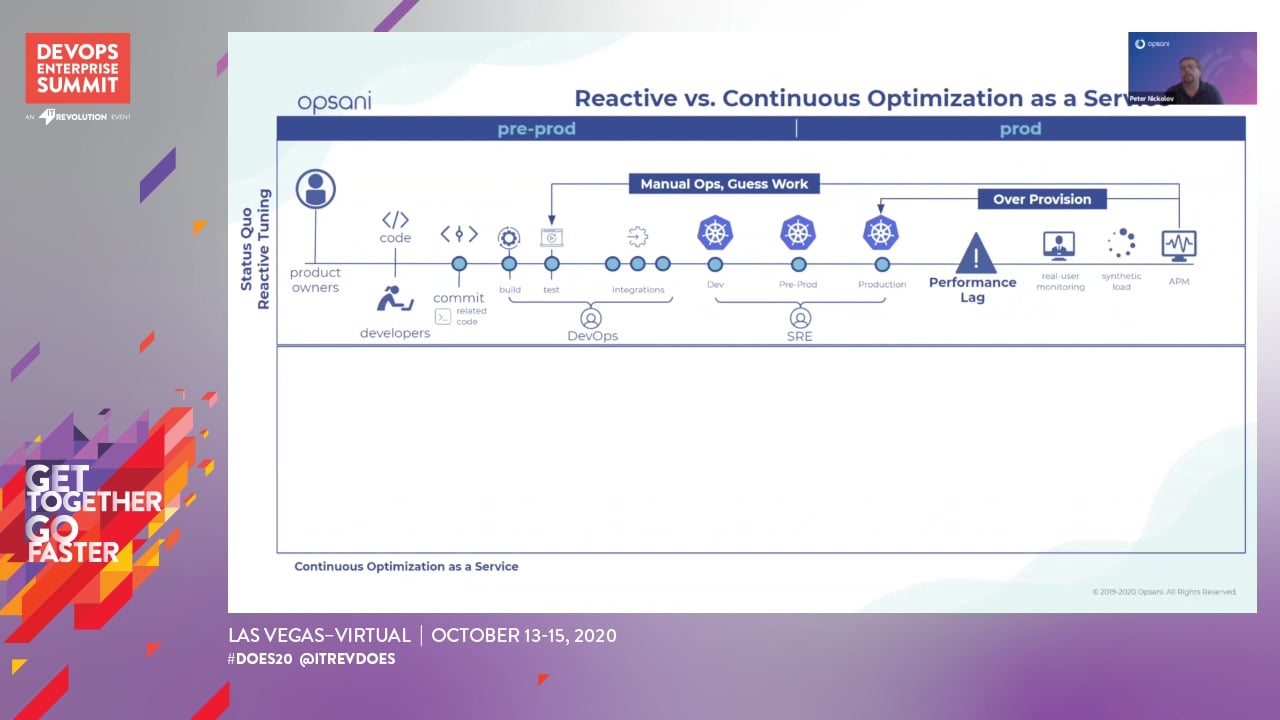
While DevOps has created software release velocity, traditional performance optimization has not been able to keep up. The result is the need to overprovision systems with CPU, memory, among other resources, all of which drive up costs unnecessarily. This problem is exacerbated as enterprises shift their software production on a services delivery platform, like Kubernetes.
The answer is performance tuning automation. Opsani, the leader in ML-driven workload configuration tuning, allows companies to tune a single service or all services across the service delivery platform autonomously. It works every time there is a code release, load profile change, or infrastructure upgrade. By discovering the service level objecting, measuring, learning, and turning to give the right resources to address the system needs predictively, Opsani continuously delivers value through higher performance, improved availability, and lower costs.
Come and learn how some of the largest enterprises have autonomously optimized thousands of their workloads across their service delivery platform with Opsani, saving countless human hours and budget dollars, while delivering better customer experience.
This session is presented by Opsani.
PN
Peter Nikolov
Founder and CTO, Opsani