Las Vegas 2020
Super-charging Software Development at Intel through DevOps
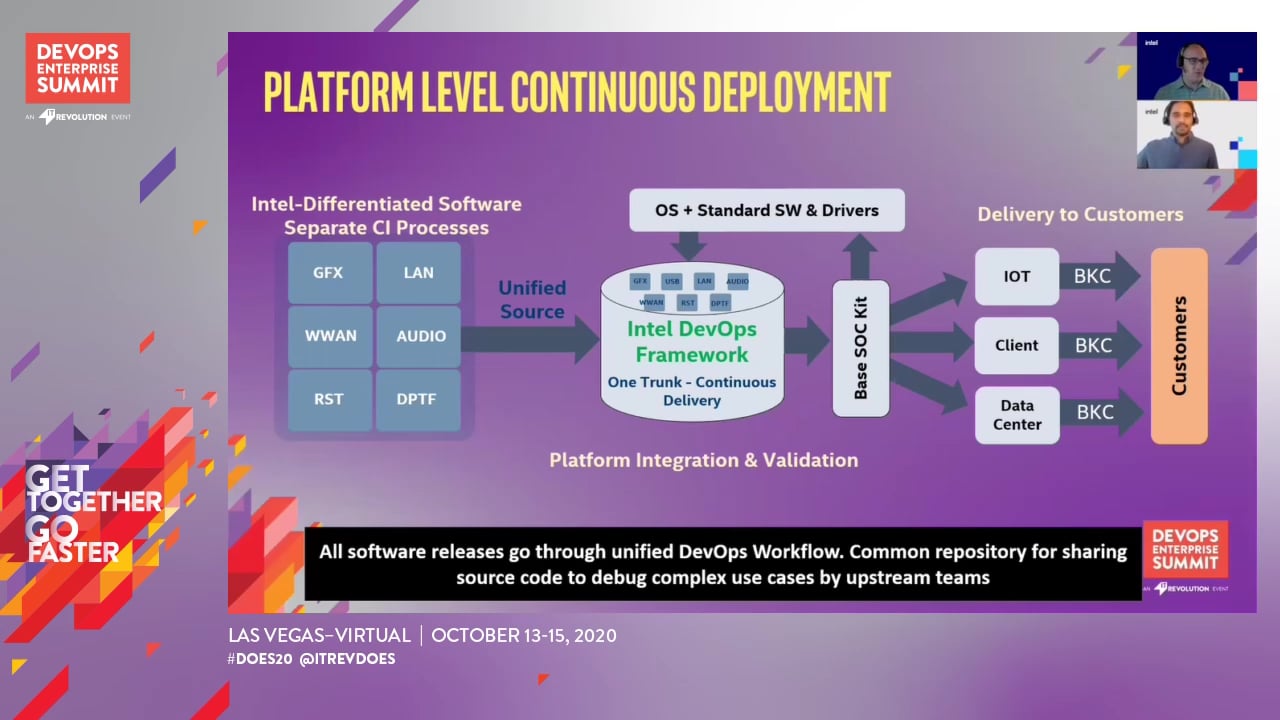
Imagine the functional and integration testing complexities involved when 20,000+ software developers distributed across 10+ countries all trying to make changes to code, testing and putting a complex system together - At Intel, we re-imagined and transformed how Devops for complex products should work at a SCALE. We have battled religious wars on tools, processes where every team across the company have already invested in their own well-established localized workflows and tools.
• How do you drive change especially in a large and diverse company such as Intel?
• How do you help teams of all shapes, sizes and different maturity level move towards faster integration cadence?
After more than half decade of change management we have lessons to share on how to approach large scale modernization using Devops and analytics solutions. Our solution is now able integrate changes across the company quickly and output a packaged software kit to our customers at 40X more capacity.
Hardware and Software co-development is becoming more and more relevant these days with uptick in device development from wearable's to software that needs to be integrated with hardware frequently. You will learn some key insights not only on Hardware and Software dependencies but also Intel's modernization efforts.
MD
Madhu Datla
Senior Engineering Manager for DevOps, Global Infrastructure and Systems Engineering Team, Intel
PT
Peter Tiegs
Principal Engineer, Intel