London 2020
12 Factor Terraform: Next Generation Infrastructure As Code
Babylon’s mission is to put an accessible and affordable health service in the hands of every person on earth.
In order to do this, we need to be able to deploy quickly, effectively, and with total confidence in success.
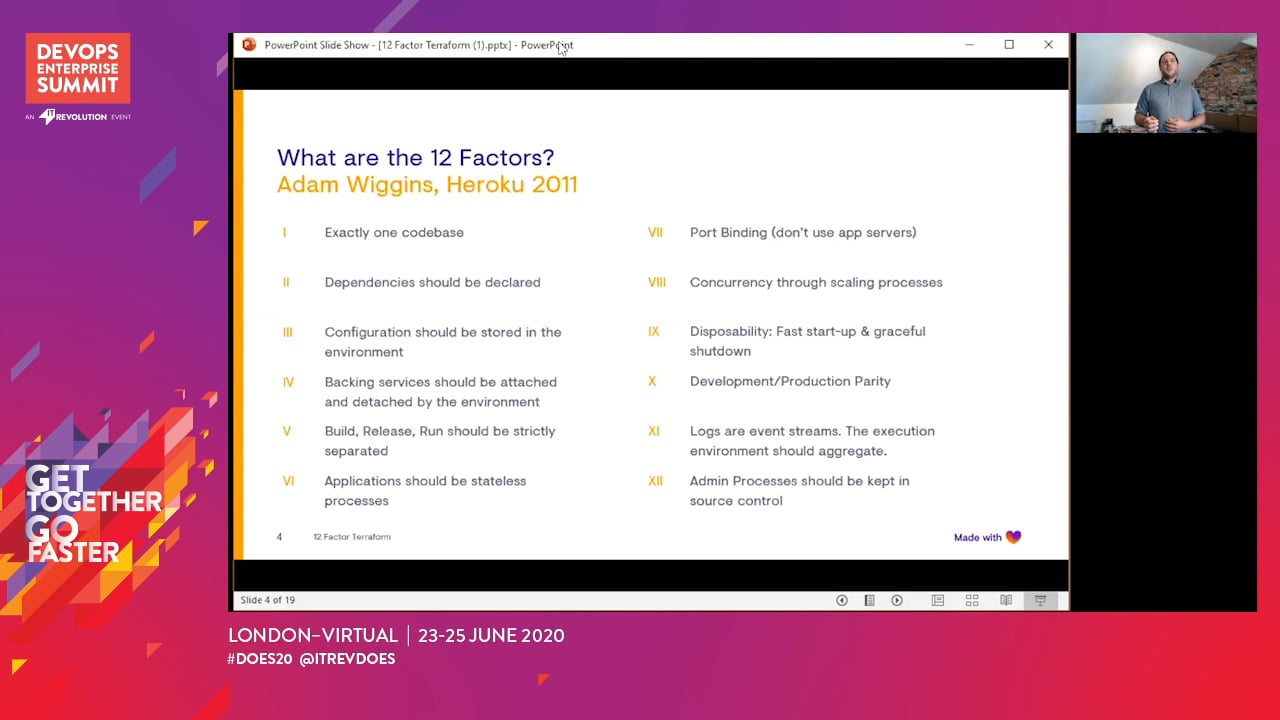
The 12 Factor App is old news as far as software development is concerned, and countless firms have achieved great success in applying its principles.
At Babylon we’ve gone a step further and have applied 12-factor principles to our IaC pipeline, and extended the concept of a microservice down to the infrastructure layer.
This means that our delivery teams are empowered to deploy their own infrastructure and innovate around it, whilst maintaining our confidence that we can allocate cost correctly, that we remain compliant with our internal and external standards, and that we are delivering as fast as we possibly can.
RV
Richard Vodden
Head of Cloud Engineering, Babylon Health