London 2020
Secrets of Developer Productivity at the Tech Giants
Google, Facebook, and Amazon have invested heavily in developer productivity, with a focus on using automation to flag performance, reliability, and security issues early in development.
They have each published extensively on their productivity experiments, describing lessons learned and best practices for incorporating static analysis and testing into DevOps workflows in a developer-centric manner.
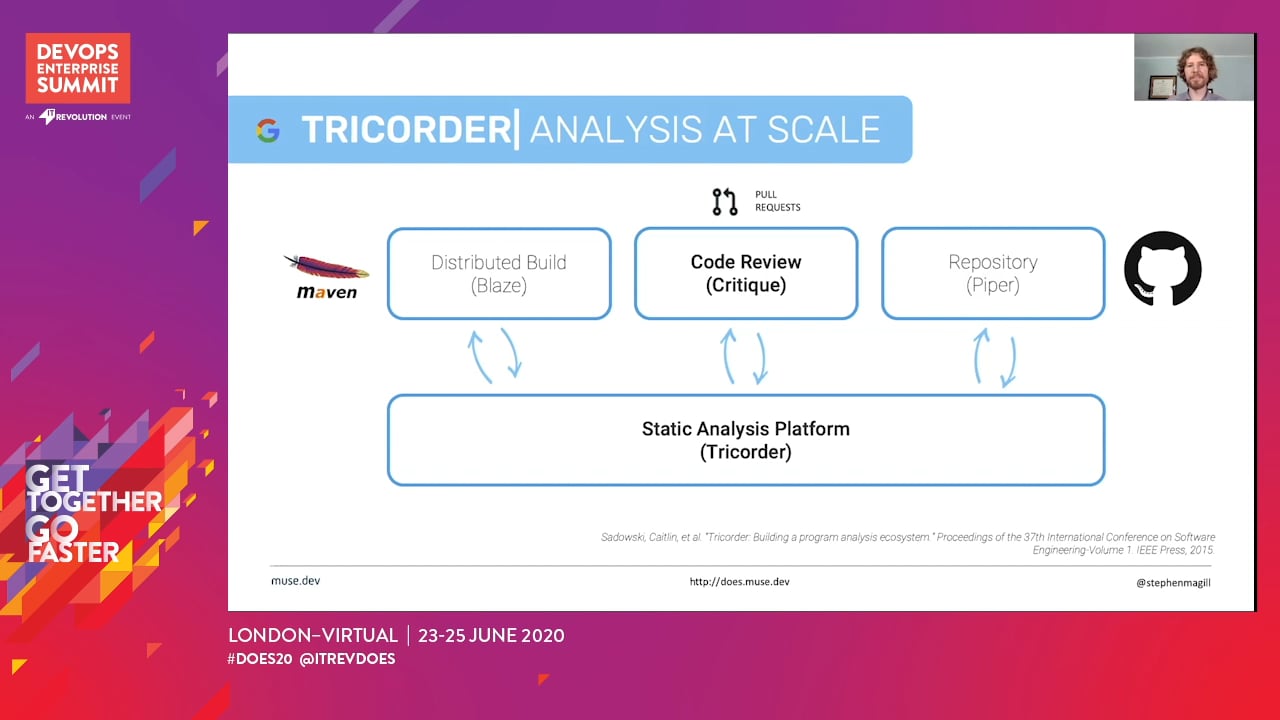
Google has developed a static analysis platform that integrates so seamlessly with the development process that many devs aren’t aware of the platform’s existence until it points out a critical vulnerability.
Facebook has integrated fuzz testing and machine-learning backed fix suggestions into their workflow in a similarly low-friction manner.
And Amazon has integrated advanced formal reasoning tools into CI processes to streamline certification reviews and catch security regressions.
What all of these efforts share is that they allow developers to recognize and fix issues themselves, without the involvement of security or QA teams, enhancing productivity of both the security / QA and development teams.
This talk will describe these automation efforts, with a focus on open source tools and integration steps that any enterprise can adopt to boost their own developer productivity and enhance software security.
DS
Dr. Stephen Magill
CEO, MuseDev