London 2020
Our First Inverse Conway's Maneuver Was Not Enough
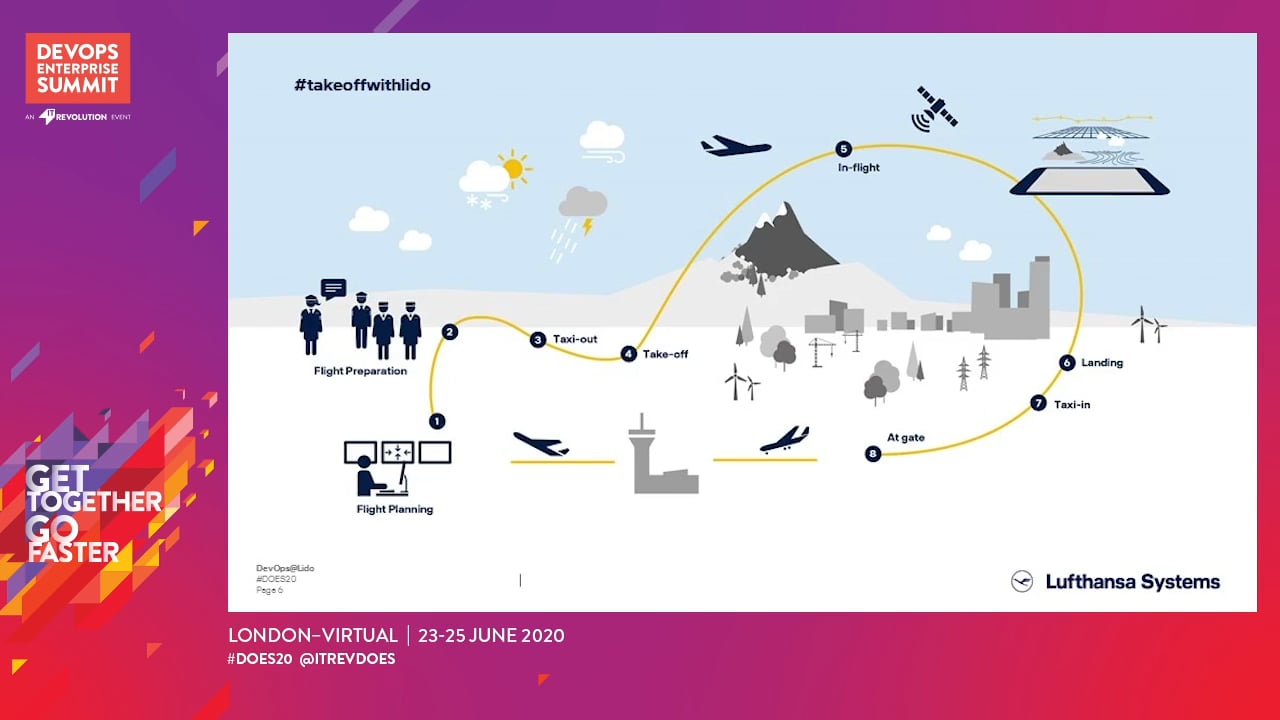
I guess you already know that there is a Conways Law.
During this session, I will not tell you too much about what it is but why we thought we should make use of it. I will share what and how we did our inverse Conways Maneuver.
Finally I will close with some insights where we still feel a lot of pain and why.
RL
Rene Lippert
DevOps Evangelist, Lufthansa Systems GmbH & Co