Las Vegas 2024
3 Ways You’re Screwing Up Platform Engineering - And How to Fix It
Why is it so easy to screw up platform engineering, and how do you undo the damage?Platform engineering… it’s the trendy new buzzword. For a thing we've all been doing for years, ever since someone said, 'What if we re-did Solaris zones but called it Docker instead?' It means building an internal engineering platform for your digital services or data pipelines. It allows you to scale teams up and down, and supercharge their abilities to deliver outcomes.But here's a thing that nobody likes to talk about. It’s easy to totally screw up platform engineering. When that happens, there’s a huge negative impact on your engineering culture, and your teams aren’t able to achieve their goals. So how do you avoid screwing up, and if it does happen to you, can you actually fix it?I’ve spent years in platform leadership roles, building internal engineering platforms at different scale-ups and enterprise organizations. I’ve had successes, and I’ve had failures. I’ll cover these screw-ups, and how to escape them:1. Power tools - teams spend all their time configuring Kafka, Kubernetes, Istio, etc., because the platform is based on overpowered, unnecessary tech2. Technology anarchy - N teams do the same task in N different ways because the platform has insufficient opinions on tech choices3. Teams as tickets - teams have to interact with the platform team via tickets, injecting per-ticket queuing delays into their delivery timelinesAnd I’ll explain why all of these can be traced back to a scaling problem, the granddaddy screw-up of platform engineering - your mindset is platform as a project, not as a product.
SS
Steve Smith
Global VP of Technology at Scale, Equal Experts
Chapters
Full transcript
The complete talk, organized by section.
Host Intro (Gene Kim)
One of the themes of this conference for the past couple of years has been platforms and platform teams. The Team Topologies book — of which one of the co-authors, Manuel Pais, is speaking later this afternoon — defines them as the specialized teams that provide a self-service platform consisting of reusable capabilities, tools, and infrastructure to streamline and support the work of other delivery teams. The concept sounds pretty simple, but unfortunately many of us have been very frustrated to see how even these simple efforts don't achieve their intended outcomes, instead frustrating all the people they touch.
So the next speaker is Steve Smith, Global VP of Technology at Scale at Equal Experts, and he will talk about three broad categories of what often goes wrong in platform initiatives. I just want to put this out there: I'm not a big fan of anti-pattern talks, but this is an exception because you present so many interesting case studies with such interesting nuances, with actual fantastic remedies. Here's Steve.
Steve Smith
[Title card on screen: "3 amazing opportunities in platform engineering which totally aren't screw ups because this is America"]
Stop that shit. Sorry, I don't know why they did that. I'm not British, I'm American like you. I'm from Quebec. That's in America, right? That's what my kids said. I said, "Name a place in America," and they said Quebec. Wasn't that a great talk by Disney? Wow — people from Disney allowed to talk about Disney. I don't know how that's legally possible. I always expect Storm Troopers to come running through when someone from Disney actually speaks out loud.
So, yes, I'm going to talk about three amazing opportunities in platform engineering — and I'm able to talk about the second part of platform engineering with you because I'm British. I'm able to talk about the problems that are inherent in it. It's easy to get it wrong. It's easy to screw up. And I know that's harder for some of my compadres here — like the John Deere talk or the Wendy's talk or the others — because in this country it's not really culturally acceptable to talk about problems out loud, is it? What we have to do is commonly disguise them as fantastical opportunities. So that's what we're going to do today. No, don't clap. Don't clap your culture. That's not what we do.
It's just how things are. It's not like Britain where we just reign in problems, is it? Now, there's one place there in America where it is okay to say out loud, "I have a problem," and not get arrested. Does anybody know where it is in America? People just flood to help you when you say "I've got a problem." I'll give you a clue: it's something to do with Jason. Someone said Disney World — that's right. In Disney World you can say out loud, "I have a problem." That's okay. The green button does that.
Yes, I'm me. I work at Equal Experts. We're a global experts-only consultancy of around 3,000 people. For ten years I've collaborated with our customers in solving their scaling problems. I've had platform leadership roles in all stages of the hockey stick in different organizations. I've written some books, including one on automating DORA metrics before they became cool — Gene didn't publish it. It's very strange. So I don't know what happened there. No book signing for me tomorrow.
So what is this platform engineering thing? The John Deere folks, the Wendy's folks talked about it in different ways. I think about it in terms of enabler teams that accelerate outcomes for delivery teams, helping them to achieve engineering excellence in terms of speed, quality, and reliability. Done well, it's a really effective solution to multiple scaling problems. For example, last year here in Vegas I talked about how to effectively manage many low-demand digital services with a few multi-product teams. You need platform engineering for that.
Also at last year's Europe event, Simon Skelton from a UK retailer called John Lewis & Partners spoke with a colleague of mine, Chris Rutter, about a security assurance problem — how do you actually ensure that teams can move fast and securely at scale? What they've done is they've built secure paved roads, they've implemented security scanning, secrets management, and observable bills of materials at the platform level. So they've unlocked security assurance and daily deployments for over 30 teams. That's what platform engineering can give you. That's the first part that everyone's going to be telling you about.
Okay, now comes the second part — the bit that Americans won't say out loud. It's easy to get platform engineering wrong. It's not because you're bad or incompetent — it's just easy to get it wrong. And you've got to fix it quickly if you do. So these are the three amazing opportunities we're going to talk about today.
01Screw-up #1: Power Tools
Our first one is power tools — that's when your platform team implements core capabilities using heavyweight tools. Maybe Kubernetes for a container runtime, or Kafka for messaging queues, or Istio as a service mesh. There are other power tools — like, please don't write to me. These are the usual suspects you'll see in the wild.
Here's a fictional American transport company to illustrate the problem. They have tracking, billing, and shipping teams consuming heavyweight tools from a well-meaning and talented platform engineering team. (It's not really an American company — there isn't — but I do like America. I went to a San Francisco 49ers tailgate last year. I got there, everyone celebrated the Brits are here, put the barbecue on, I said, "None of that, just give me a giant bag of Cheetos." We can't get them in the UK. I ate them all by myself, didn't share. We went through stadium security — I was covered in orange dust. The security guard said I looked like an incompetent drug mule.)
Power-tool capabilities need a lot of all-round effort. There's a steep learning curve, there's a lot for your platform team to build and run, and there's a lot for your delivery teams to maintain as well — there's a lot of configuration and custom integrations that creep in that are beyond their core competencies often.
So how do you measure the positive and negative impact of power tools? You do it the way you would any platform capability — use the same three metrics.
One is internal customer value — that's the extent to which you are accelerating your teams in speed, quality, and reliability. That's something Amy and her friends covered in the John Deere talk today — Justin and Adam, when they were talking about the value prop for their developer platform. Metric number two is internal customer cost — that's how much unplanned tech work your platform generates for your teams. That's the fifth of four DORA metrics. Google don't really talk about it anymore. What else are they hiding from us? It's very mysterious. And three is your platform cost. Don't think about your cloud bills — think about the number of platform engineers you'll need to actually operate this thing. How much build-and-run work is incurred?
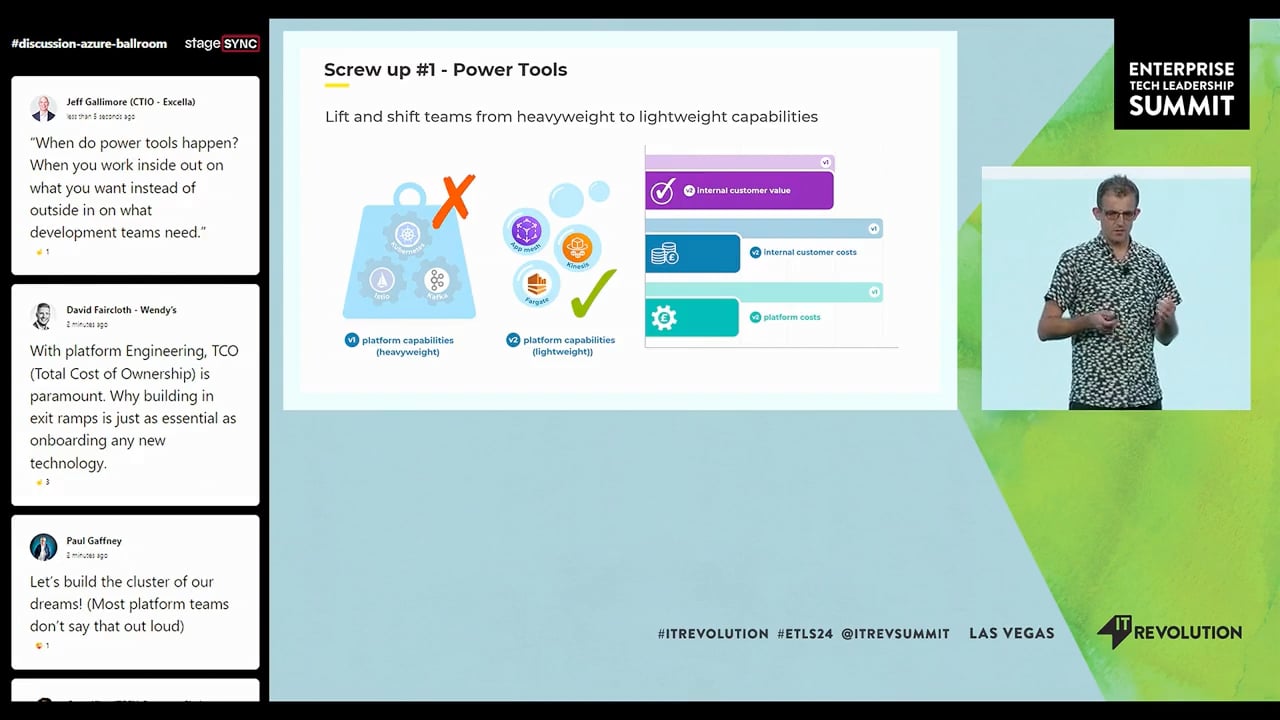
Here's a visualization of how internal customer value, internal customer costs, and platform costs usually appear for power tools, in my experience. We want value to be high and costs to be low — like, I'm not an idiot — but often with power tools you have all three really high. That's because with power tools they can deliver the internal customer value you're looking for — I've seen it done a few times — but all too often it simply doesn't happen, and there's a huge commitment to make here in terms of time and effort and money because it takes a long time to get them right. There's so much unplanned tech work that's created — the total cost of ownership is just off the charts — and your platform costs (shown here in green) are also really high because you need a lot of people to operate these things.
What does power tools feel like? I've listened to the platform engineering experiences of customers across the Equal Experts network and I have some badly anonymized examples to share. (I don't have to remember which one is which here, so don't try and catch me out.)
We've got a platform lead at an American broadcaster who couldn't build a platform because their engineers kept fighting to use Kubernetes on Azure and the delivery teams kept fighting to not use Kubernetes because they said it would slow them down. The platform engineers won, after three months of arguing, then spent three months building the cluster of their dreams. So that's six months down the drain. What the hell — I guess we're making enough money.
And second, there's a tech lead in German e-commerce — this one is my absolute favorite. Their platform team self-managed an Istio service mesh, and the tech lead and other delivery teams found that the platform just didn't move fast enough for them. That's because the platform team were a bit wary of doing upgrades, because they tended to go bang when they upgraded Istio. The official upgrade plan wasn't always 100% accurate, but there was a Dutch company they found online who would go first and helpfully publish on their company blog how they did the upgrades and how they deviated from the official plan. This German company had no business relationship with this Dutch company. This Dutch company didn't know the German company existed. But the German company had a dependency in its project planning on the Dutch company — and one German engineer was voluntold to learn Dutch to read that blog. So that's when it's time to 'fess up. You've got a problem when you've got engineers being told to learn Dutch. It's time to 'fess up — you know what, like, we're screwing this one up here.
Power tools happen when your platform team works inside-out on the tools they want, not outside-in on the tools your delivery teams need. Kubernetes, Kafka, and Istio — they are good power tools, but specifically within the context of platform engineering, they simply don't offer enough unique internal customer value to justify their total cost of ownership. Not in 2024. Please don't start using them tomorrow.
So you've got some power tools already. You've screwed up. How do we get out of it? You lift and shift your teams from heavyweight to lightweight capabilities. You find the capability with the highest internal customer costs. You call it version one. You lock it down so that new services can't use it. You build a lighter-weight version of that capability. You make all your net new services use it. You call that version two. And then migrate teams across as fast as you can.
Here's our American transport company again — their platform team has created similar capabilities, but this time with Fargate, Kinesis, and App Mesh, and they look like pretty fluffy bubbles, so they're going to be lighter. What does this all mean? It means three things can happen: you have a similar internal customer value, you have lower internal customer costs because teams know less and do less, and you have lower platform costs — you won't need as many operators to look after this thing, you can save some money there. Good.
02Screw-up #2: Technology Anarchy
All right, our second screw-up is technology anarchy. This is when your platform gives delivery teams the autonomy they need to make choices for themselves, but it doesn't give them the technical alignment they need to make good choices overall for your organization.
Back to our American transport company. They've got a CI/CD capability built on top of GitHub. It doesn't offer much technical alignment. So three teams obviously are going to choose three different tech stacks — one's in Java, one's in Python, one's in Scala. That means they manage their own N CI/CD pipelines. (It's not really an American company, is it? But I do like America. At last year's event we went for some drinks after the event, and the Cosmo waitress kept saying to me, "Would you like your drinks in takeaway cups?" I didn't know that was American for "get out." So I just kept saying, "No thanks, we are good here." After an hour she lost her temper, got an enormous dude from the kitchen — he came out and said, "Get out." Answered that just fine. Why didn't you speak in British in the first place? We'd have saved an hour of everyone's lives.)
Lots of teams, lots of pipelines, lots of tech stacks. That means lots of end-to-end testing madness, lots of test environments, lots of quirky, inefficient deployers. If one pipeline breaks, the platform team can't help you. You're on your own. If you want to move people between teams for capacity challenges, you can't do that — people will resist it, they won't want to learn a new tech stack for another team. Or alternatively, you might need to keep them where they are because of the amount of tacit knowledge they have. That's something that David and Hanni touched on in the Wendy's talk today. And if you want to exit GitHub because GitLab dumps a truckload of mangoes in your CTO's swimming pool, then that's a load of separate migrations to GitLab. Is this conference GitHub or GitLab sponsored? I can't remember. Is it GitHub? Oh, doesn't matter, they're not going to hire me.
So when a platform capability doesn't provide technical alignment, it's providing some internal customer value, which is good, but it's simply not going to push your teams far enough. The out-of-the-box offering isn't enough. And your internal customer costs are astronomical because teams have to build so much of their technical solutions for themselves. There's a lot of unplanned tech work here. There's a lot of inefficiencies, a high cognitive load. There's no economies of scale.
What does technology anarchy feel like? First, we've got a delivery manager at a British telco. They invited me to visit in person — this was pre-pandemic. "You like 'you build it, you run it,' don't you, Steve?" "I do." "We've got 20 teams on GCP. You should come and see." So I came and saw, and what I saw was not a lot of progress on team boards. I asked innocently, "Where's the platform team?" They looked blank, and I got that sick feeling you get in your stomach. It turned out they didn't have a platform team. So 20 teams were doing GCP in 20 subtly different ways. The delivery manager said to me, "What should we do?" I said, "Well, you've probably got a lot of unplanned tech work happening here. It's hard to measure, it's hard to automate. Just ask your teams once a week what percentage of their time is being spent on unexpected GCP reconfiguration, and if it's more than 10% you need a platform team." It was 55%. The delivery manager was disgusted. Like, don't hate the player, that's not my fault.
Second, we have a head of engineering at an American retailer. She had 10 teams with 10 different RabbitMQ messaging solutions. An architect decided everyone should be using Kafka for consistency. So that was 10 unique migrations, which took months to complete, because Kafka is a power tool with a steep learning curve and it's easy to get it wrong. Morale took a real hit in that organization.
When does technology anarchy happen? When you unnecessarily sacrifice technical alignment because you believe you can't have it and autonomy at the same time. You can. Here's a 2x2 of alignment and autonomy that I cooked up a couple of years ago. It's based on some work with Spotify and Crisp — a Swedish consultancy that I visited in Stockholm a while back. I do like Spotify, although they get very angry if you don't need their ceremony or pickled fish every morning.
The legacy of the Spotify model isn't tribes, chapters, and the other one. It's the idea that you can embed aligned autonomy into a technology organization. Most organizations here, I'm willing to bet, are in the top left or the bottom right. Autocracy in the top left is when you have a lot of alignment but it's command and control, top-down rules. So you can't have any autonomy there. Or you're in the bottom right — technology anarchy, which we're talking about here — that's where you give your teams a lot of autonomy to increase speed, but without giving them something to replace those rules. There's no technical alignment and there's going to be mistakes. You need to be in the top right. That's where you have a high degree of alignment, but it's contextual. It's guidelines, not rules. And you still have autonomy there.
All right, so you've got technology anarchy, you've screwed it up. How do you get out of it? You ask your engineering leaders for three things: guidance on tech stack and architecture, their expectations of what that looks like, and then the business consequences for everybody if their expectations aren't met. You capture that technical alignment in decision records. You bake it into your platform capabilities, into your paved roads. You ask teams to bake it into their own solutions in their digital services, and then you periodically verify that's what's happening.
If this sounds familiar to this morning, that's good, because in the SiriusXM talk, that's exactly what Ben, Rachel, and Carol were talking about. It's been a privilege to be a small part of the journey of that company. They've really brought to life aligned autonomy in a really exciting way. And I mean exciting in a British sense, where I'm actually telling the truth — not the American way where you're not quite sure what you mean.
Here's our American transport company again. They've created a single GitHub template for everybody. It offers one reliable test environment, observability instead of end-to-end testing madness, and a canary deploy that actually works. The catch is that teams just have to bend Java and Scala to use Python. And guess what? If you give developers a thing that just works, they'll use it. They aren't actually that fussed about someone else's tech stack.
So here teams aren't involved in platform decisions anymore. People are able to move faster. What does it all mean? It means there's a positive impact on speed, quality, and reliability because there's less end-to-end testing madness. Teams are picking up organizational best practices for free, and teams don't have to build and maintain so many technical solutions. So internal customer costs come down — and that's what we're really looking for. And yes, your platform costs go up, but that's an acceptable trade-off to make, right? You want high customer value, low customer costs, and you manage your own costs.
03Screw-up #3: Ticketing Hell
All right, our final screw-up is ticketing hell. This is when your platform team is like an ops service desk. They do everything for your delivery teams — provisioning, configuration, deployments, on-call support — and it all happens through Jira or another ticketing system.
Let's have another visit to our American transport company. They've got a bunch of platform capabilities in AWS, and everything has to be done via a mountain of tickets. (It's not really an American company, but I do like America. I took my kids to a Florida waterpark. Their lunch app needed a 10-digit US mobile number. I have an 11-digit UK mobile number, which is superior. I went to the counter and said, "How does your lunch app work? I've got a problem." They ran away and hid in the kitchen. My children went hungry. I realized I made the mistake there, not them. That wasn't poor customer service — what I should have done is said, "Here's an amazing opportunity to help my family. I really messed up." Or we should have gone to Disney World.)
A lot of tickets means only one thing: lots of queues. Teams waiting on the platform team to action their work. When platform capabilities are ticket-driven, internal customer value is low — your platform team just won't keep up with demand. Internal customer costs are low. That's good — but that's because not much is happening. Your platform costs are like out of space because you need so many platform engineers to try and keep up with demand. You won't be able to do it. You'll end up embedding platform engineers inside delivery teams, and that's when it's time to admit it. It's like learning Dutch — you've got a problem.
Ticketing hell feels like this: we've got a tech lead, a new starter at a Dutch bank, on day one. They filed a ticket asking for access to code repositories. The platform team actioned it after 11 weeks. So they just felt unproductive — they had to work on other people's laptops. Their new team told them to get used to it. That's what life's like. We are a bank.
And second, we've got a delivery manager at an Australian telco. At that company, any deploy to any environment requires a ticket. So that manager spends their days just massaging, maintaining, managing tickets through the platform team — who just can't keep up with demand. It's just a combinatorial explosion.
Ticketing hell happens when you forget about handoffs, when you don't optimize for them. Here's a platform backlog, just as a linear sequence. The billing team's ticket is at the back. The estimate is it needs one day of platform team time. But this isn't going to take one day — this is going to take six days because there's a handoff. They're in an invisible queue, and they're incurring a five-day penalty because there's five days of work ahead of them. That isn't necessarily visible to the delivery team themselves.
This is what happens whenever technology leaders allow functional specialists — DBAs, change managers, platform engineers — to intentionally or unintentionally silo themselves away. Don't let that happen.
So you've got ticketing hell, you've screwed it up — how do you get out of it? You make your workflow self-service. You measure different tasks the platform team has to do. You prioritize what's going to move the needle for delivery teams right now. You give teams access to a self-service workflow. You do this incrementally — you don't make everything self-service all at once, obviously. And you visualize a fully automated audit trail in a platform portal, so teams and stakeholders can understand actions and impacts, and your whole organization can gain confidence in those self-service workflows.
One final trip to our American transport company. They've created v2 self-service pipelines for common capabilities. Delivery teams can move much faster. The platform team has fewer tickets. What does it all mean? It means a massive uptick in internal customer value because teams are unblocked — they can move much faster. And there's a lower platform build cost. Yes, you have to build those self-service workflows, but there's far fewer tickets to work on forever. You'll need fewer engineers, which is good — they're expensive.
04Takeaways
All right, what have we learned? Not much. When you examine what's underneath these screw-ups — when it's your job to think very deeply about platform engineering, which is my job — there's really one takeaway here: if you don't have a product mindset in platform engineering, you will fail. You could have central funding, you could have a platform product manager, you could have really talented engineers — those are all really important things, but if you don't have that product mindset, it will go wrong. If your platform team thinks your platform's a project, they'll fail. If they think they're gatekeepers, not enablers, they'll fail. If they think build-it-and-they-will-come actually works like it doesn't, then they'll fail.
You need to increase internal customer value, reduce internal customer costs, and manage your platform costs.
This community's all about actively helping each other. I'd like to hear more about these platform engineering screw-ups. I'd like to be able to help more organizations to avoid them in the future. So if you've seen them before in the wild, please do come and talk to me. I'd really appreciate it.
Thank you to Gene for inviting me to speak here. I'll tell you a secret about Gene that he kind of gave away a little bit there — he doesn't like anti-pattern talks. So I'm counting on you to give your best American whoops and cowboy hats in the air, so that Gene will actually invite me back and be like, "Maybe this anti-pattern thing, it can work sometimes."
But if you'd like to talk about high-performance platform engineering, digital transformation, come and talk with me or my American colleagues, and we'd love to help you. Thank you.